
こんにちは、のっくん(@yamagablog)です。
ようやくGPUでディープラーニングができるようになったので、犬と猫の画像を判別してみたいと思います。
パソコンを買ってからGPUを設定するまでの苦労話は以下の記事にまとめてあります。
【Ubuntu】TensorflowやKerasをGPUで動かす方法
いやー長かった。
動かせるようになっただけで満足ですが、せっかくなので何かコードを書いてみたいと思います。
[toc]
使用するデータセット
kaggleというサイトから犬と猫の画像データセットをダウンロードします。
https://www.kaggle.com/c/dogs-vs-cats/data
25000枚ほど入ったzipファイルがありますのでその一部を使います。
ディレクトリの作成
訓練、検証、テスト用のディレクトリを作ります。
それぞれのフォルダには犬と猫のそれぞれのフォルダを作っておきます。
.
├── test
│ ├── cats
│ └── dogs
├── train
│ ├── cats
│ └── dogs
└── validation
├── cats
└── dogs
ファイルのコピー
オリジナルのデータセットから以下の枚数だけ、上で作成したディレクトリにコピーしたいと思います。
- 訓練用 – 2000枚
- 検証用 – 1000枚
- テスト用 – 1000枚
訓練用画像のコピー
犬、猫、それぞれ1000枚の画像をそれぞれ訓練用画像にします。
ファイル名は、cat.{0-999}.jpgのように連番になっているので、0-999の数字をfor文で回します。
以下の例ではリスト内包表記で書いています。
fnames = ["cat.{}.jpg".format(i) for i in range(1000)]
for fname in fnames:
from_data = original_dataset_dir + "/" + fname
to_data = train_cats_dir + "/" + fname
shutil.copyfile(from_data, to_data)
fnames = ["dog.{}.jpg".format(i) for i in range(1000)]
for fname in fnames:
from_data = original_dataset_dir + "/" + fname
to_data = train_dogs_dir + "/" + fname
shutil.copyfile(from_data, to_data)
検証用画像のコピー
犬と猫、それぞれ500枚ずつを検証用画像とします。
fnames = ["cat.{}.jpg".format(i) for i in range(1000,1500)]
for fname in fnames:
from_data = original_dataset_dir + "/" + fname
to_data = validation_cats_dir + "/" + fname
shutil.copyfile(from_data, to_data)
fnames = ["dog.{}.jpg".format(i) for i in range(1000,1500)]
for fname in fnames:
from_data = original_dataset_dir + "/" + fname
to_data = validation_dogs_dir + "/" + fname
shutil.copyfile(from_data, to_data)
テスト用画像
テスト用画像も同様です。
fnames = ["cat.{}.jpg".format(i) for i in range(1500,2000)]
for fname in fnames:
from_data = original_dataset_dir + "/" + fname
to_data = test_cats_dir + "/" + fname
shutil.copyfile(from_data, to_data)
fnames = ["dog.{}.jpg".format(i) for i in range(1500,2000)]
for fname in fnames:
from_data = original_dataset_dir + "/" + fname
to_data = test_dogs_dir + "/" + fname
shutil.copyfile(from_data, to_data)
ファイル数の確認
ファイル数の確認には、`os.listdir`の長さを数えます。
print("train cat:{}".format(len(os.listdir(train_cats_dir))))
print("train dog:{}".format(len(os.listdir(train_dogs_dir))))
print("validation cat:{}".format(len(os.listdir(validation_cats_dir))))
print("validation dog:{}".format(len(os.listdir(validation_dogs_dir))))
print("test cat:{}".format(len(os.listdir(test_cats_dir))))
print("test dog:{}".format(len(os.listdir(test_dogs_dir))))
出力は以下の通り。
train cat:1000 train dog:1000 validation cat:500 validation dog:500 test cat:500 test dog:500
ネットワークの作成
ネットワークを作成します。
from keras import layers from keras import models model = models.Sequential() model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3))) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Conv2D(64,(3,3),activation="relu")) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Conv2D(128,(3,3),activation="relu")) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Conv2D(128,(3,3),activation="relu")) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Flatten()) model.add(layers.Dense(512,activation="relu")) model.add(layers.Dense(1,activation="sigmoid")) model.summary()
最後の層の活性化関数には、sigmoidを使います。
from keras import optimizers
model.compile(loss="binary_crossentropy",
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=["acc"])
今回のような2値分類では、活性化関数は「sigmoid」、損失関数は「binary_crossentropy」を使うのが一般的みたい。
データの前処理
学習にかけるためには、画像ファイルに以下の前処理をしておきます。
- 画像ファイルを読み込む。
- 浮動小数点数型(float型)にする。
- ピクセル値(0-255)を、[0,1]の範囲の値にする
kerasの`ImageDataGenerator`を使うとこの処理を自動的にやってくれます。
なんて便利なのでしょう。
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150,150),
batch_size=20,
class_mode="binary"
)
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
target_size=(150,150),
batch_size=20,
class_mode="binary"
)
- target_sizeは、画像のサイズです。上では150,150のサイズにリサイズします。
- batch_sizeは、一度に処理する画像の枚数です。20枚を1バッチとします。
- class_modeは、”binary”として二値のラベルを作成します。
内容を確認。
for data,label in train_generator:
print(data.shape)
print(label.shape)
break
(20, 150, 150, 3)
(20,)
学習
訓練用は2000枚あるので1バッチ20枚処理するとすると100ステップ必要になります。
history = model.fit_generator(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
validation_stepsは、評価用のバッチをいくつ取り出すか決めるようです。
検証用は1000枚なので、1バッチ20枚とすると、50ステップ指定すれば良いですね。
正解率の可視化
import matplotlib.pyplot as plt %matplotlib inline acc = history.history["acc"] val_acc = history.history["val_acc"] loss = history.history["loss"] val_loss = history.history["val_loss"] epochs = range(1,len(acc) + 1) plt.plot(epochs, acc,"bo",label="Training Acc") plt.plot(epochs, val_acc,"b",label="Validation Acc") plt.legend() plt.figure() plt.plot(epochs,loss,"bo",label="Training Loss") plt.plot(epochs,val_loss,"b",label="Validation Loss") plt.legend() plt.show()
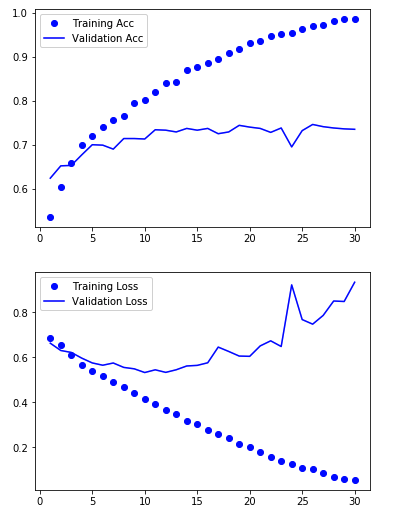
バリデーションの正解率は、70%-74%ほどになっています。
そこそこ分類できているようですね。
次はデータ拡張にトライしてみたいと思います。
Udemy
Udemyの無料講座でもディープラーニングについて説明していますのでよろしければどうぞ。
https://www.udemy.com/course/deeplearning-practice-dogcat/learn/lecture/29144680#overview
参考









