
Pandasのデータフレームで、データを抽出したり、ソートしたり、関数を使う方法をご紹介します。
[toc]
使用するデータ
適当に自分で作った以下のCSVデータを使います。
id,name,genre,type,rating 9,Guide of google adsence,Blog,Book,5 108,AI and Machine Learning,Programming,Book,4 31,Bootstrap 4,Programming,Book,2 16,SOFT SKILLS,Software,Book,3 89,Django begginer,Programming,Book,3 90,Fast and Furious,Car,Movie,3
本や映画の名前、ジャンル、評判などからなる6行のデータです。
これを読んで表示します。
book = "./data/book_list.csv" df = pd.read_csv(book) df
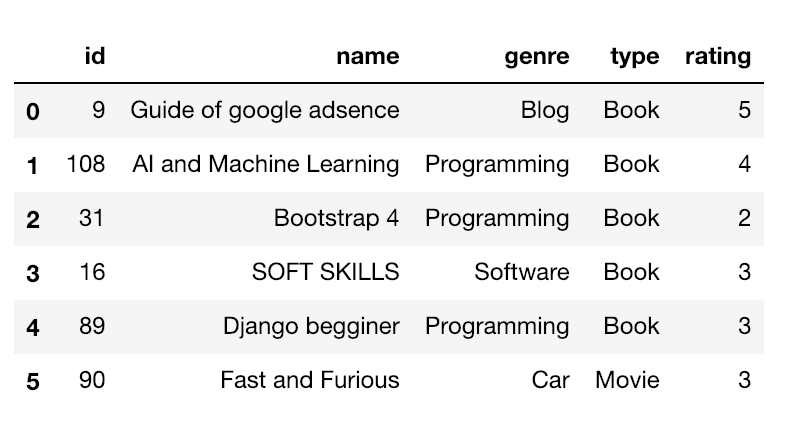
一行目がデータではなくラベルとして認識されました。番号も自動的に割り振られます。
データを抽出する
locを使ったデータの抽出
ジャンル(genre)がプログラミングのものだけ取り出してみます。`loc`を使います。
df.loc[df['genre'] == 'Programming']

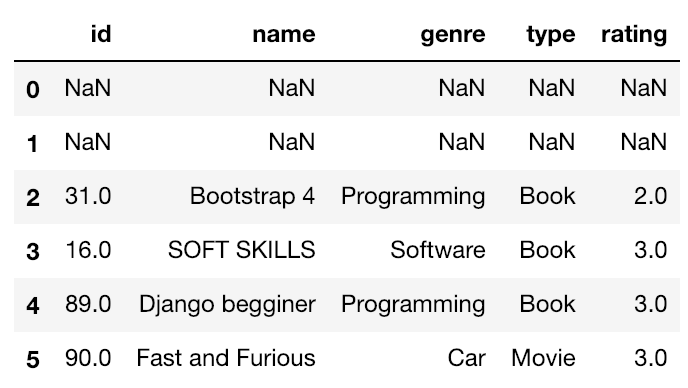
whereを使ったデータの抽出
locを使うと条件に合わないデータは表示されませんでした。whereを使うと条件に合わないデータはNaN(欠損値)として、表示されます。
df.where(df['rating'] < 4)
データをソートする
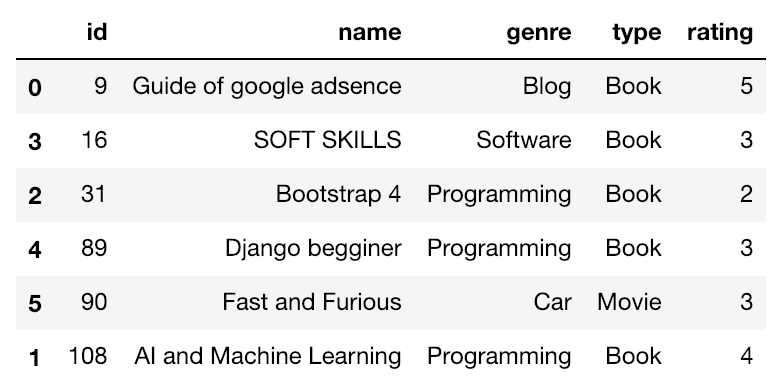
id順に並べてみます。
# 昇順
df.sort_values('id')
降順で並べる場合は、`ascending = False`を引数に追加します。
データフレームに関数を適用する
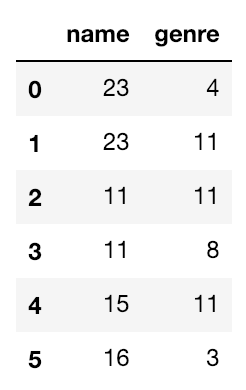
pandasでは、`applymap`を使うことでデータフレームに関数を適用することができます。
例えば、上記データのタイトルやジャンルの文字列の長さを取得したい場合、ラベルを指定してlen関数を適用することで文字列の長さを計算できます。
df[['name','genre']].applymap(len)
おわり。







