こんにちは。のっくんです。
今日の記事では、webページにあるサッカーのランキング表をスクレイピングする方法を紹介します。
「Pythonでテーブルのスクレイピングがしたい」
そんな方に読んでいただければと思います。
[toc]
テーブルとスクレイピング
[speech_bubble type=”ln” subtype=”L1″ icon=”ilust/cat2_4_think.png” name=”ネコ”]スクレイピング??テーブル?よく分からないニャー。[/speech_bubble]
[speech_bubble type=”ln” subtype=”L1″ icon=”profile_face.png” name=”のっくん”]ごめん、ごめん。いきなり専門用語が出てきたね。詳しく説明するよ。[/speech_bubble]
テーブルと言うのは、HTMLの1つの要素です。
以下のサッカーの順位表ページを見てください。
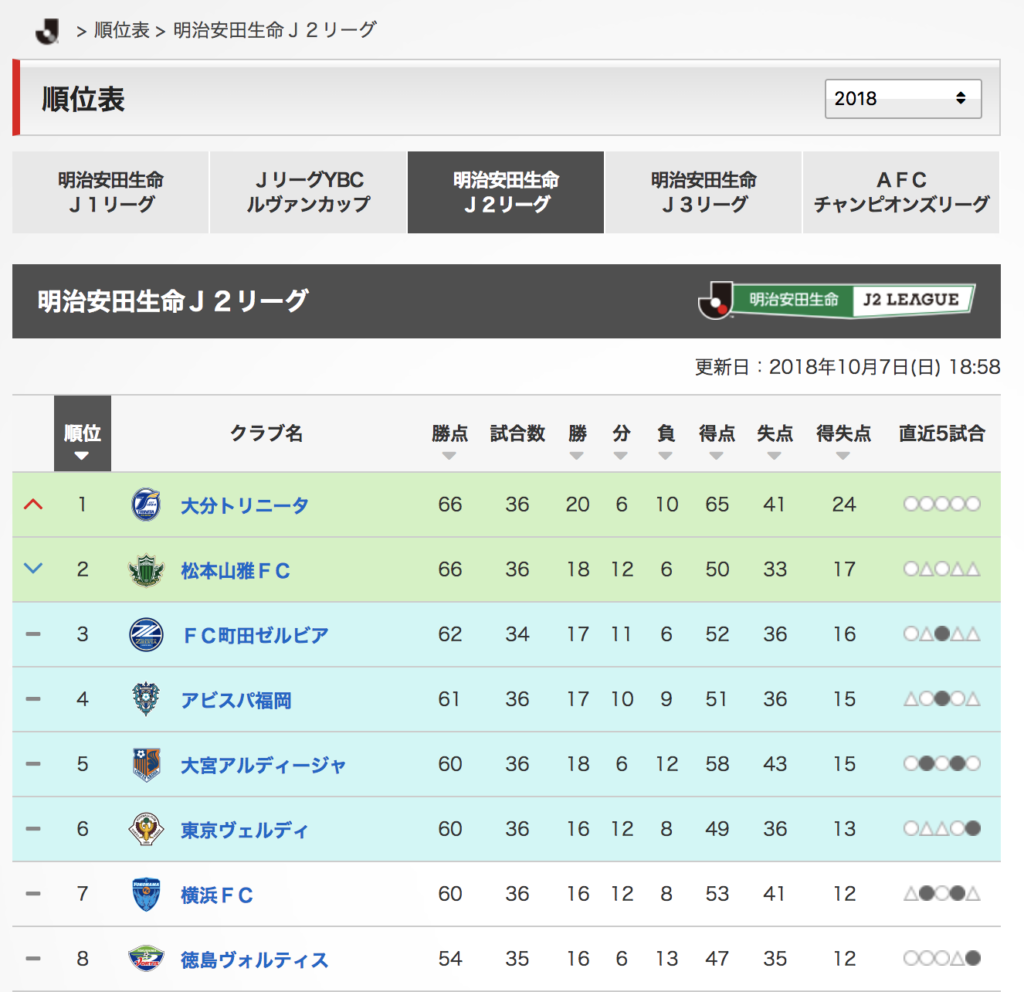
https://www.jleague.jp/standings/j2/
このランキング表がHTMLのテーブルでできています。先週まで首位だった松本が2位なのは非常に悔しいですが、、、
スポーツのサイトだけでなく、以下のような本を販売するサイトでも使っています。

https://www.oreilly.co.jp/ebook/
本のタイトルや価格、出版日が表になっていますよね。これもHTMLのテーブルで作られているんです。
このように特定のサイトだけでなく、ほとんど全てのサイトで使われているのがHTMLのテーブルなんです。
スクレイピングというのは、ウェブサイトから自分が欲しい情報を抜き出して取得することです。本屋の例でいうと、本のタイトルや価格だけ抜き出すってイメージですね。
[speech_bubble type=”ln” subtype=”L1″ icon=”ilust/necchusyou_face_boy1.png” name=”少年”]つまりテーブルをスクレイピングするってことは、ウェブサイトの表データを抜き出して取得するって事なんだね。
[/speech_bubble] [speech_bubble type=”ln” subtype=”L1″ icon=”profile_face.png” name=”のっくん”]その通り!次の章からプログラムの説明に入っていくよ。[/speech_bubble]
テーブルの構造
スクレイピングを始める前に、HTMLのテーブルの構造を理解しておきましょう。
<table>
<tr>
<td>商品名</td><td>値段</td>
</tr>
<tr>
<td>おーい、お茶</td><td>100円</td>
</tr>
</table>
この<>で囲まれたものはタグと呼ばれます。<table>であればテーブルタグと言います。
色んなタグが出てきましたね。それぞれ以下のような意味を持ちます。
<table> …表の始まりであることを示す
<tr> …行の始まりであることを示す
<td> ~ </td> …セルであることを示す
</tr> …行の終わりであることを示す
</table> …表の終わりであることを示す
http://www.newcredge.com/IT/www/html/tag/table/table-tr-td.html
このように、どこにどんなデータが入っているかはタグによって定義されています。
データが格納されている場所がタグによって定義されているので、タグの中身を取得することで必要な情報をスクレイピングすることができます。
つまり、tableタグ、trタグ、tdタグの順番で追っていけば欲しい情報が手に入るということです。
タグの中身を順番に追っていくというのは今回のプログラムの肝になりますので、覚えておいて下さいね。
[speech_bubble type=”ln” subtype=”L1″ icon=”ilust/cat2_4_think.png” name=”ネコ”]うーん。難しいけど、必要な情報がある場所は定義されているからそこを見に行けば良いってことなのかニャ。[/speech_bubble] [speech_bubble type=”ln” subtype=”L1″ icon=”profile_face.png” name=”のっくん”]その通りだよ。次の章からはいよいよPythonのコードを書いていくよ。[/speech_bubble]
コーディング
テーブルの構造を理解すると、どのデータを取得するべきかが分かります。
tableタグの中のtrタグのtdタグの中に欲しい情報が入っているんだな。ということが分かればあとはそれを順番に取得するコードを書いていきます。
必要なライブラリのインストール
今回のプログラムを作るために、BeautifulSoupというライブラリが必要です。
Anaconda Navigator(もしくはpip)を使ってインストールしてください。
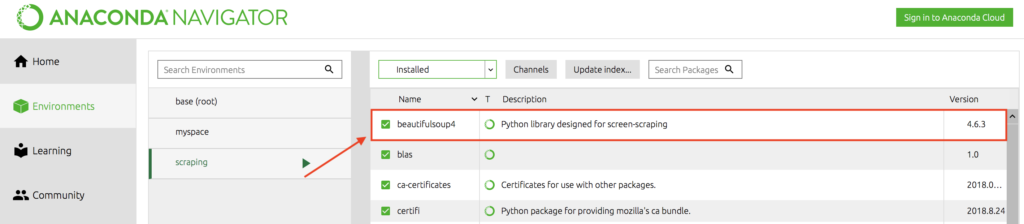
インストールが終わると、上記のように表示されます。
プログラム
エディタで以下のようにプログラムを書きます。
scraping_j2_table.py
import csv
from urllib.request import urlopen
from bs4 import BeautifulSoup
# URLの指定
html = urlopen("https://www.jleague.jp/standings/j2/")
bsObj = BeautifulSoup(html, "html.parser")
# テーブルを指定
table = bsObj.findAll("table", {"class": "scoreTable01 J2table tablesorter"})[0]
rows = table.findAll("tr")
csvFile = open("ranking.csv", 'wt', newline='', encoding='utf-8')
writer = csv.writer(csvFile)
try:
for row in rows:
csvRow = []
for cell in row.findAll(['td', 'th']):
csvRow.append(cell.get_text())
writer.writerow(csvRow)
finally:
csvFile.close()
テーブルタグ内にクラス名がある場合には、クラス名を指定することでそのテーブルのみを取り出すことができます。
- クラス名が「scoreTable01 J2table tablesorter」のテーブルタグ内にあるtrタグのリストを取得します。
- trタグの中にある、tdタグもしくはthタグの中に書かれているテキストをget_textを使って取得します。取得したテキストはcsvRowリストに加えていきます。
- trタグ内のパースが終わったら、それをcsvに書き出します。
- 全てのtrタグに対して、2と3を繰り返し行う。
実行結果は以下の通り。
ranking.csv
,順位,クラブ名,勝点,試合数,勝,分,負,得点,失点,得失点,直近5試合 ,1,大分トリニータ大分トリニータ,66,36,20,6,10,65,41,24, ,2,松本山雅FC松本山雅FC,66,36,18,12,6,50,33,17, ,3,FC町田ゼルビアFC町田ゼルビア,62,34,17,11,6,52,36,16, ,4,アビスパ福岡アビスパ福岡,61,36,17,10,9,51,36,15, ,5,大宮アルディージャ大宮アルディージャ,60,36,18,6,12,58,43,15, ,6,東京ヴェルディ東京ヴェルディ,60,36,16,12,8,49,36,13, ,7,横浜FC横浜FC,60,36,16,12,8,53,41,12, ,8,徳島ヴォルティス徳島ヴォルティス,54,35,16,6,13,47,35,12, ,9,モンテディオ山形モンテディオ山形,51,36,13,12,11,43,43,0, ,10,レノファ山口FCレノファ山口FC,51,35,13,12,10,59,61,-2, ,11,ツエーゲン金沢ツエーゲン金沢,49,36,13,10,13,45,40,5, ,12,ファジアーノ岡山ファジアーノ岡山,49,36,13,10,13,36,37,-1, ,13,ヴァンフォーレ甲府ヴァンフォーレ甲府,48,35,13,9,13,51,41,10, ,14,水戸ホーリーホック水戸ホーリーホック,47,36,13,8,15,40,39,1, ,15,ジェフユナイテッド千葉ジェフユナイテッド千葉,45,36,13,6,17,63,65,-2, ,16,栃木SC栃木SC,45,36,12,9,15,34,42,-8, ,17,アルビレックス新潟アルビレックス新潟,45,36,13,6,17,42,51,-9, ,18,愛媛FC愛媛FC,43,36,11,10,15,31,43,-12, ,19,京都サンガF.C.京都サンガF.C.,34,36,9,7,20,35,51,-16, ,20,FC岐阜FC岐阜,33,36,9,6,21,39,59,-20, ,21,ロアッソ熊本ロアッソ熊本,27,36,7,6,23,42,72,-30, ,22,カマタマーレ讃岐カマタマーレ讃岐,26,35,6,8,21,25,65,-40,
無事、取得できていますね。
#2018/10/11日追記
チーム名がダブってる問題は、以下のように直すことで対応できました。
try:
for row in rows:
csvRow = []
for cell in row.findAll(['td', 'th']):
# <td>の中にspanがある場合はチーム名が2つ取れてしまう。
if cell.find('span'):
csvRow.append(cell.span.get_text())
else:
csvRow.append(cell.get_text())
writer.writerow(csvRow)
finally:
csvFile.close()
最後まで読んでいただきありがとうございました.