
この記事では、kerasを使ってMNIST(エムニスト)データセットの学習、テストにチャレンジしてみます。
解説を交えながら、jupyterノートブック上で順番にコードを実行していきたいと思います。
[toc]
事前準備
kerasとtensorflowを使うので、pipで入れておきましょう。
それが終わったら、使用するライブラリをimportします。
バッチサイズや分類するクラス数、エポックの数もここで決めておきます。
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers.core import Dense, Dropout, Activation from keras.optimizers import RMSprop from keras.callbacks import EarlyStopping, CSVLogger %matplotlib inline import matplotlib.pyplot as plt #訓練データの1個のデータ数 batch_size = 128 # 分類するクラス数 num_classes = 10 # 誤差逆伝播法の繰り返しの回数 epochs = 20
MNISTデータセットの中身
どんなデータを扱うのか、中身をみてみます。
(x_train,y_train),(x_test,y_test) = mnist.load_data()
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(y_test.shape)
for i in range(10):
plt.subplot(2,5,i+1)
plt.imshow(x_train[i].reshape(28,28),cmap=None)
plt.show()
実行結果は以下の通り。

28*28の正方形の画像データが、学習用に6万枚、テスト用に1万枚あるようです。
データの変換
このままだと学習に使用できないので、データの形式を変換します。
# 二次元(28*28)を一次元(784)に変換
x_train = x_train.reshape(60000,784).astype('float32')
x_test = x_test.reshape(10000,784).astype('float32')
# 0-1に正規化
x_train /= 255
x_test /= 255
# クラス数をセット
y_train = keras.utils.to_categorical(y_train,num_classes)
y_test = keras.utils.to_categorical(y_test,num_classes)
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(y_test.shape)
実行結果は以下の通り。

データとラベルがそれぞれ一次元に変換できました。
モデルの作成
逐次モデルを作っていきます。以下のような3層のニューラルネットを作ってみます。
一層目:
- Dense → Activation → Dropout
- 784次元のデータを任意の数だけ入力、出力は512次元
- activationには、reluを指定
- dropoutで約2割の入力ユニットを0にする
二層目:
- Dense → Activation → Dropout
- 512次元の入力データ、出力は512次元
三層目:
- Dense → Activation
- 入力は512次元、出力は10次元
- activationにはsoftmaxを指定
model = Sequential()
model.add(Dense(512,input_shape=(784,)))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(10))
model.add(Activation('softmax'))
model.summary()
サマリーの出力は以下の通り。
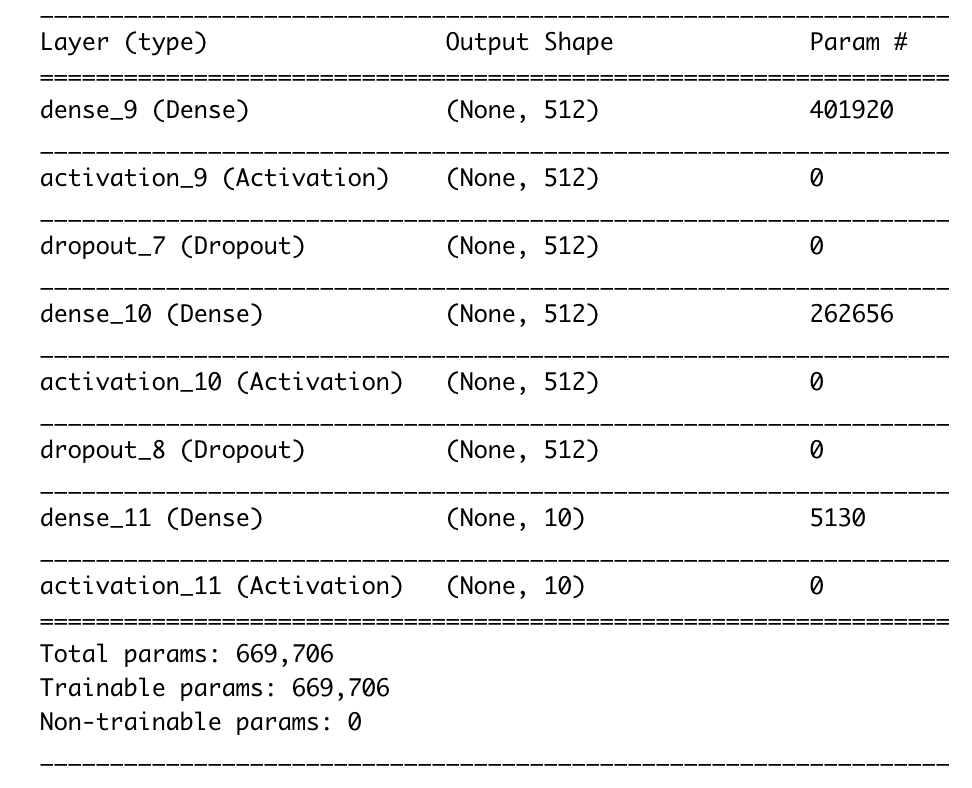
Paramは、入力と出力の次元を掛け合わせた値になっています。例えば最初の層は、
(784+1) * 512 = 401920
となります。+1はバイアスが追加されているからです。
学習
定義したモデルで学習してみます。ポイントは以下の通り。
学習を行う:
- lossの基準にクロスエントロピーを指定
- EarlyStoppingはある程度学習が進んだら、早期終了する
- CSVLoggerを使って、学習結果を保存する
model.compile(loss="categorical_crossentropy",
optimizer=RMSprop(),
metrics=['accuracy'])
es = EarlyStopping(monitor='val_loss',patience=2)
csv_logger = CSVLogger('training.log')
hist = model.fit(x_train,y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1,
callbacks=[es,csv_logger])
実行すると4回でEpochが終了したようです。

acc=精度をみるとどんどん上がっているのが分かります。
テスト
score = model.evaluate(x_test,y_test,verbose=0)
print('test loss:',score[0])
print('test acc:',score[1])
test loss: 0.06666695135778282 test acc: 0.9812
約98%の精度で判別できました。
学習結果の可視化
loss = hist.history['loss']
val_loss = hist.history['val_loss']
epochs = len(loss)
plt.plot(range(epochs),loss,marker='.',label='loss(training data)')
plt.plot(range(epochs),val_loss,marker='.', label='val_loss(evaluation data)')
plt.legend(loc='best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show
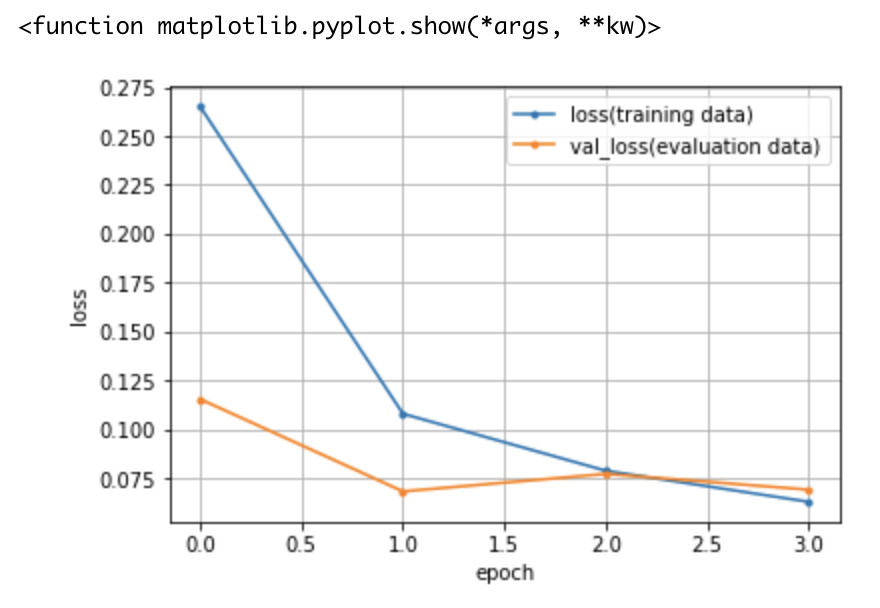
グラフのように、学習データに対する損失は下がっています(=精度は上がっている)が、テストデータに対する損失はあまり下がっていません(=精度が上がらない)。
この現象は過学習と呼ばれています。









