こんにちは、のっくんです。
今日はPythonのrequestsとBeautifluSoupを使って、wikipediaの情報をスクレイピングしてみたいと思います。
スクレイピングする対象は以下のwikipediaにします。
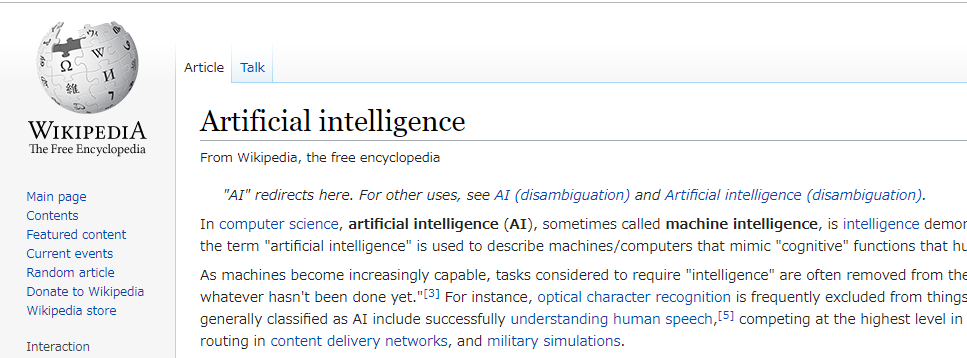
https://en.wikipedia.org/wiki/Artificial_intelligence
英語のページで字数も多いので、見るのが嫌になりそうなページです。
字数が多いですが、ビューティフルスープを使って高速にスクレイピングを体験できるので、最初の題材としては良いと思います。
海外のサイトでもwikipediaの情報をスクレイピングしているものが多いので、練習にはもってこいです。
[toc]Requestsを使ってWikipediaのページを取得する
まずは、必要なモジュールをインポートしましょう。
import requests from bs4 import BeautifulSoup
もしモジュールが見つからないエラーがでる場合は、パッケージ管理ソフトであるpipやcondaでインストールをしてください。
Googleの提供するGoogle Colaboratoryというクラウドで実行できる環境には予めパッケージが入っています。
次に、URLを指定して、ページの情報をゲットします。
target_url = 'https://en.wikipedia.org/wiki/Artificial_intelligence' r = requests.get(target_url)
うまくいくと、以下のコードでリターンコードを表示すると200番が表示されます。
404番が表示される場合には、URLが間違っている可能性がありますので確認しましょう。
ブラウザでURLを入力してページが表示されるか確認するのが1番よいです。
print(r.status_code)
BeautifulSoupを使ってタグをスクレイピング
取得したHTMLの内容をテキスト情報にしてBeautifulSoupに渡します。
この時にHTMLパーサを指定するように引数に指定します。
soup = BeautifulSoup(r.text, "html.parser")
ページの下の方にいくと、See Alsoという欄があり、そこに内部リンクが多数掲載されています。
Google Chromeで右クリックして「ページの検証」を押すと、タグ名と該当するエリアが半透明になります。

スクレイピングでは、この該当するエリアのタグ名が大事になります。
今回は、「div.div-col-columns.column-width」が必要な情報になります。
divタグの中に欲しい情報があることが分かったので、コードを書いていきます。
findを使って以上のdivタグの中身を取得します。
第二引数にはクラス名を指定します。
このときにアンダーバーを忘れないようにしましょう。
# find("タグ名"、class_="クラス名 クラス名 クラス名")で指定する
div_tag = soup.find('div', class_='div-col columns column-width')
取得したデータはprintを使って確認できます。
print(div_tag)

リンクは、liタグの中のaタグの中のhref属性にあることが分かりました。
順番にスクレイピングしていきます。
まずは、liタグを取得しましょう。
liタグは複数あるので、find_allを使います。
li_tags = div_tag.find_all('li')
そして取得したliタグの1つ1つからaタグのhref属性を抜き出し、リストに追加(append)していきます。
リンクのついでにテキスト情報も一緒にリストに追加します。
scraped_list = []
for li in li_tags:
# aタグのhref属性の抽出する
href = li.find('a')["href"]
text = li.find('a').getText()
scraped_list.append((href,text))
print(scraped_list)
リストの中身は以下の通り。
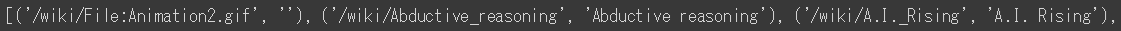
内部リンクとテキスト情報を取り出すことができました。
ファイルに保存する
取得した情報は以下のコードでCSVファイルに保存することができます。
with open('scraped_list.csv', 'w') as f:
for i in scraped_list:
f.write(",".join(i)+"\n")
おわり。