こんにちは、のっくんです。
今日は、ディープラーニングで「ながら運転」を検知するコードを書いていきたいと思います。
「Distracted Driver」ディストラクティッド?ドライバーと読むみたいですが、ググったら「ながら運転」と翻訳が出てきたのでそう書きました。
「よそ見運転」とも言うかもしれません。
データセットはいつもの通り、kaggleと言う競技サイトにありました。
https://www.kaggle.com/c/state-farm-distracted-driver-detection
State Farmと言う会社が、よそ見運転している画像を集めて提供してくれているようです。
(なんて良い会社)
kaggleの良いところはアカウント登録をするだけで誰でもデータセットをダウンロードできるところ。
このサイトによると、アクシデントの5回に1回はながら運転によるものだと書いてあります。
このデータセットですがなんと4GBありまして、ダウンロードに時間がかかりました。
データ量が少なければGoogle Colabにアップしてコードを書くのですが、データ量が多いとアップロードにものすごく時間がかかります。(クラウドなので。。)
今回は家のGPU付きのPC(Ubuntu)にデータをアップロードして、コードを書いていきたいと思いま〜す。
まずは中身をチェック!
いつものようにデータセットの中身をみていきます。
Jupyter上では、「!」を最初につけることでLinuxのコマンドが使えます。
unzipして中身を解凍してみます。
!unzip "state-farm-distracted-driver-detection.zip"
中にあった”driver_imgs_list.csv”というCSVファイルを見つけました。
この中にディープラーニングのヒントになる情報が入っているはず。
csvファイルの解析にはpandasを使います。
まずはこのファイルからどんなデータセットであるか把握したいと思います。
df = pd.read_csv("driver_imgs_list.csv")
head()を使うと、最初の5行だけデータを表示することができます。
df.head()
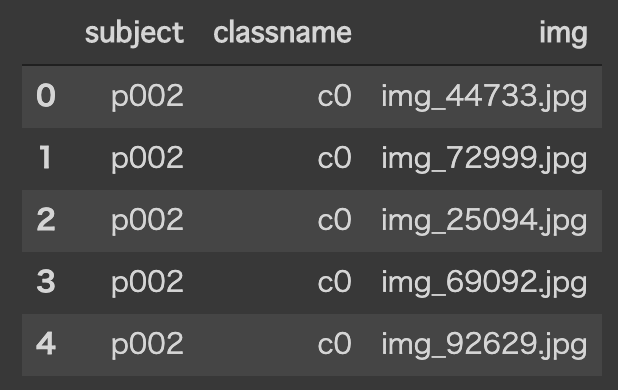
classnameが今回分類したいカテゴリーです。
よそ見運伝かそうでないかの二値分類ではなく、よそ見運転の種類を予測する多クラス分類のようです。
よそ見の運転でも、「ジュースを飲んでいる」、「スマホを操作している」など色々あるのでそれを画像からAI(ディープラーニング)で分類する問題です。
imgが、画像ファイル名になっています。(subjectはよく分からん。)
画像ファイル名に1から順番に番号が振ってあると読み込みしやすいんですけど、今回はそうではないみたいです。
ファイル名の命名規則がクリアになっていると、コードが書きやすくなります。
なぜかと言うとファイル名がわかっていれば、予めファイル名を指定して読み込みができるからです。
例えば、最初の1000枚だけを読みたい場合は、1~1000の番号を指定すれば良いですからね。
まぁ今回のようにランダムな数値であっても、指定の枚数だけ読み取る方法はあります。
次に画像が合計で何枚あるか調べてみます。
データフレームの行数を見れば分かるはず。
pandasで行数と列数を見るには、shapeを指定します。
df.shape # (22424, 3)
なんと22424行、つまりそれだけ画像ファイルがあります。
3は3列という意味で、先ほどの[subject],[classname],[img]を指しています。
次に、classnameがいくつあって、それぞれで何枚の画像があるのか、集計してみたいと思います。
列ごとに集計をするには、列名を指定してvalue_counts()を実行します。
df["classname"].value_counts() # c0 2489 c3 2346 c4 2326 c6 2325 c2 2317 c5 2312 c1 2267 c9 2129 c7 2002 c8 1911 Name: classname, dtype: int64
c0からc9まで10種類あることが分かりました。
それぞれのクラスで約2000枚の画像があるようです。
分類するべきカテゴリーの数や画像の枚数というディープラーニングに必要な情報が取得できました。
必要なヒントが得られたので、次からもう少し踏み込んだ内容に入っていきたいと思います!
おわり。