
Googleニュースを好きなキーワードで自動的に取得できたら便利ですよね。
今回の記事では、自分の好きなキーワードを入力して、ニュースを自動的に取得するコードをPyhtonで書いてみましょう。
[toc]
Googleニュース
Googleニュースは検索すると出てくると思いますが、こんな感じのものです。
キーワードを入れると自分の好きなニュースが取得できます。私はサッカーが好きなので、
j2リーグと検索します。もちろん、好きなキーワードを入れていただいて構いません。
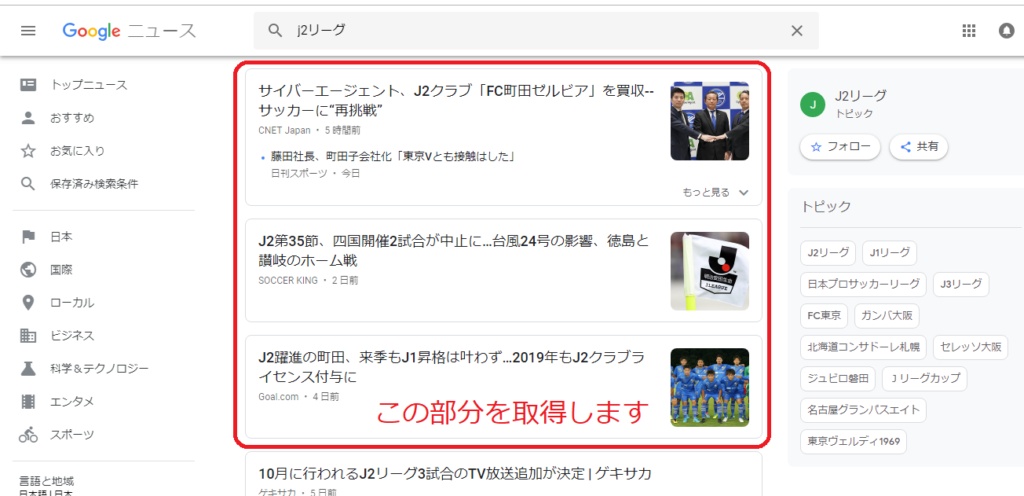
赤枠の部分がニュース記事です。今回はこのニュースをPythonを使って取得してみましょう。
feedparserをインストールする
feedparserは、anacondaでもpipでもインストールできます。
anacondaを使っている方は、anaconda navigatorで検索、pipでインストールしたい方は以下のようにしてください。
$ pip install feedparser
URLを決定する
コーディングに入る前に、Googleのニュース(RSSフィード)を取得するためのURLを決める必要があります。
https://news.google.com/news/rss/search/section/q/★/★?ned=jp&hl=ja&gl=JP
この★の部分に、検索キーワードを入れます。今回の検索キーワードは「j2リーグ」ですが、そのまま入れるわけではなく、URLエンコーディングします。
試しに、下のサイトでutf-8を選択してURLエンコーディングしてみます。
http://charset.7jp.net/urlchg.html
「j2リーグ」 → 「j2%e3%83%aa%e3%83%bc%e3%82%b0」
こんな感じでURLエンコーディングされた文字列が出てきました。これを★に入れてコード内で使用します。
https://news.google.com/news/rss/search/section/q/j2%e3%83%aa%e3%83%bc%e3%82%b0/j2%e3%83%aa%e3%83%bc%e3%82%b0?ned=jp&hl=ja&gl=JP
2018/11/29日追記:
Pythonでは、URLエンコーディングするためのライブラリが用意されてましてこれを使うと自動でできました。
s = 'j2リーグ'
# URLエンコーディング
s_quote = urllib.parse.quote(s)
url = "https://news.google.com/news/rss/search/section/q/" + s_quote + "/" + s_quote + "?ned=jp&hl=ja&gl=JP"
コーディング
それでは、コーディングしていきましょう。
処理としては、
- urlをfeedparserでパースする
- ニュース記事リストを、for文で回して各記事のタイトルやソートキーを取得
- 最後に日付順にソート
ソートキーというのは日付を羅列した数値です。これを元にソートすることで、記事を投稿順に表示することができます。
get_google_news.py
import feedparser
import json
import pprint
# RSSのスクレイピング
url = 'https://news.google.com/news/rss/search/section/q/j2%e3%83%aa%e3%83%bc%e3%82%b0/j2%e3%83%aa%e3%83%bc%e3%82%b0?ned=jp&hl=ja&gl=JP'
d = feedparser.parse(url)
news = list()
for i, entry in enumerate(d.entries, 1):
p = entry.published_parsed
sortkey = "%04d%02d%02d%02d%02d%02d" % (p.tm_year, p.tm_mon, p.tm_mday, p.tm_hour, p.tm_min, p.tm_sec)
tmp = {
"no": i,
"title": entry.title,
"link": entry.link,
"published": entry.published,
"sortkey": sortkey
}
news.append(tmp)
news = sorted(news, key=lambda x: x['sortkey'])
pprint.pprint(news)
enumerateを使うと、for文のループ回数を取得できます。取得した記事の順番に1,2…と番号を振っています。
実行結果は以下の通り。
{'link': 'https://japan.cnet.com/article/35126348/',
'no': 1,
'published': 'Mon, 1 Oct 2018 03:49:17 GMT',
'sortkey': '20181001034917',
'title': 'サイバーエージェント、J2クラブ「FC町田ゼルビア」を買収--サッカーに“再挑戦”'},
{'link': 'https://www.soccer-king.jp/news/japan/jl/20181001/840884.html',
'no': 15,
'published': 'Mon, 1 Oct 2018 04:23:40 GMT',
'sortkey': '20181001042340',
'title': '20回目の「創設の日」を迎えたFC東京、新スタジアム建設の可能性に言及'},
{'link': 'https://news.nifty.com/article/sports/soccer/12192-840905/',
'no': 18,
'published': 'Mon, 1 Oct 2018 10:32:00 GMT',
'sortkey': '20181001103200',
'title': '台風24号の影響で中止…徳島vs甲府、代替開催日が10月16日に決定'}]
下の方が、新しい記事になっています。台風でヴァンフォーレ甲府の試合が中止になったみたいですね。汗
こんな感じで短いコードでさくっと記事を取得できるようです。
取得した記事をjson形式で保存したい場合は、以下の通り。json.dumpで保存、json.loadで読み取りです。それぞれ2行で書けるのは素晴らしいですね。
with open('news.json', 'w') as f:
json.dump(news, f)
with open("news.json", 'r') as f:
data = json.load(f)
ちなみに、スクレイピングしたデータは以下のページで公開しています。
http://nokkun.pythonanywhere.com/news
まとめ
・日付順にソートするためには、ソートキーを作成しよう
・データはjsonで保存すると楽








