こんにちは。のっくん(@yamagablog)です。
今日の記事ではScrapyを使ってヤフーニュースをクローリングする方法をご紹介します。
[speech_bubble type=”ln” subtype=”L1″ icon=”ilust/shinpai_man.png” name=”男の子”]クローリング?Scrapy?なんだか難しそうだなぁ。。。[/speech_bubble] [speech_bubble type=”ln” subtype=”L1″ icon=”profile_face.png” name=”のっくん”]大丈夫。Scrapyは基本的な機能を全部提供してくれるので、使う方は大まかな内容を書くだけでいいんだよ。[/speech_bubble]
[toc]
始める前に
まず開発環境ですがMacです。途中でMacのコマンドを使って作業しています。Windowsでも同じようにできるかも知れませんが、その場合は適宜置き換えて理解してください。
開発環境
・MacBook Pro 13 inch
・Anaconda
・Python 3.6
Scrapyのプロジェクトを作成する
クローリングにはscrapyを使います。scrapyはクロールをするためのフレームワークです。
プロジェクトを作成してその中でクロールするコードを書いていきます。プロジェクトを作成するところはDjangoなどのフレームワークと同じです。
私はAnacondaユーザなのでAnacondaナビゲータを使って、Scrapyをインストールしました。(もちろん、pipでもインストール可能です。)
Scrapyをインストールしたら、以下のコマンドでプロジェクトを作ります。
(scraping) bash-3.2$ scrapy startproject myproject
プロジェクトの構成は以下の通り。
(scraping) bash-3.2$ tree . ├── myproject │ ├── __init__.py │ ├── __pycache__ │ ├── items.py │ ├── middlewares.py │ ├── pipelines.py │ ├── settings.py │ └── spiders │ ├── __init__.py │ └── __pycache__ └── scrapy.cfg
settings.pyに以下の1行を追加して、ページのダウンロード間隔を1秒空けます。
DOWNLOAD_DELAY = 1
itemの作成
itemはデータを格納するためのオブジェクトです。Djangoでいうmodelと同じです。
記事のタイトルと内容を格納するフィールドを以下のように定義します。
import scrapy
class Headline(scrapy.Item):
title = scrapy.Field()
body = scrapy.Field()
Spiderの作成
以下のコマンドで、Spiderを作成します。第一引数にはSpiderの名前、第二引数にはドメイン名を指定します。プロジェクトのルートディレクトリでコマンドを実行してください。
(scraping) bash-3.2$ scrapy genspider news news.yahoo.co.jp
実行すると、spidersディレクトリの中にnews.pyができます。ここにコードを追記していきます。
各記事のリンクの抽出
まずはトップページにある各記事へのリンクを取得してみましょう。
news.py
import scrapy
class NewsSpider(scrapy.Spider):
name = 'news'
allowed_domains = ['news.yahoo.co.jp']
start_urls = ['http://news.yahoo.co.jp/']
def parse(self, response):
print(response.css('ul.toptopics_list a::attr("href")').extract())
このparseの処理ですがCSSセレクタを使ってHTMLのタグやクラスを指定しています。タグやクラス名はサイトの作成者が変更する場合があるので自分で確認するのが良いです。
URLに関しては、aタグのhrefの中にあるのでそれも一緒に指定してます。
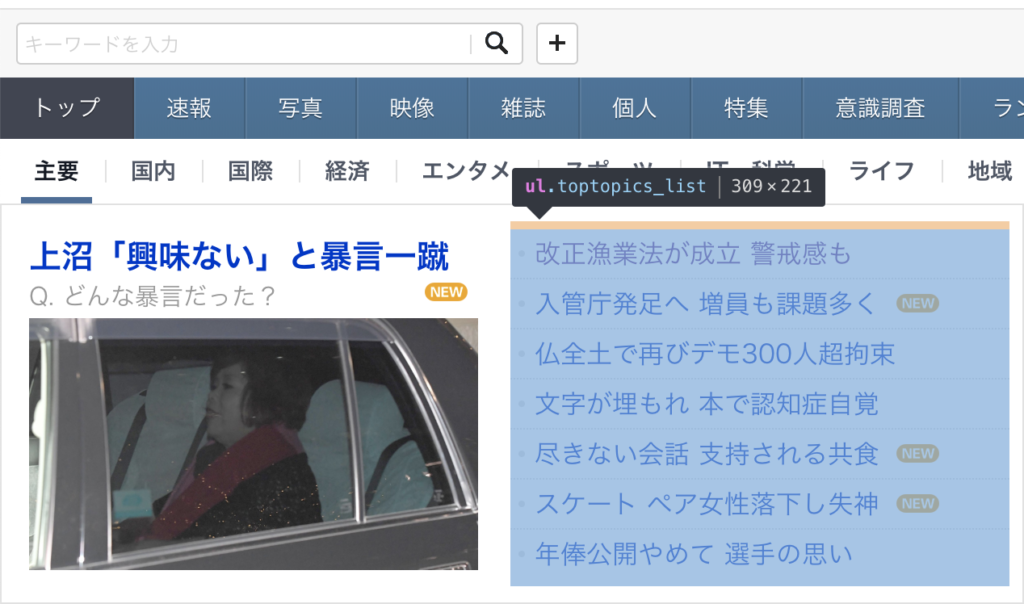
私はChromeの開発者ツールを使って確認しました。
他のウェブサイトのコードをチェックできるツールです。詳しい使い方は以下のページを見て下さい。
https://saruwakakun.com/html-css/basic/chrome-dev-tool
以下のコマンドでクロールを開始します。
(scraping) bash-3.2$ scrapy crawl news
2018-12-09 00:36:18 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) ['https://news.yahoo.co.jp/pickup/6306067', 'https://news.yahoo.co.jp/pickup/6306073', 'https://news.yahoo.co.jp/pickup/6306056', 'https://news.yahoo.co.jp/pickup/6306063', 'https://news.yahoo.co.jp/pickup/6306074', 'https://news.yahoo.co.jp/pickup/6306077', 'https://news.yahoo.co.jp/pickup/6306075', 'https://news.yahoo.co.jp/pickup/6306069', 'https://news.yahoo.co.jp/list/', 'https://news.yahoo.co.jp/topics']
上のように記事のリンクがリストで返ってきたら成功です。(そのままだと見にくいので手動で改行してます。)
クロールする
次に、各記事のタイトルの内容を集めてきて保存するコードを書いていきます。
記事へのリンクを見ると、
‘https://news.yahoo.co.jp/pickup/6306069’
のようになってます。
/pickup/数字列
が含まれたリンクだけ取り出したいです。この数字列の表現ですが正規表現にすると、
任意の数字が一回以上出現する
ってことになります。任意の数字は「\d」,一回以上は「+」,文字列の末尾は「$」で表します。
re(r'/pickup/\d+$')
[speech_bubble type=”ln” subtype=”L1″ icon=”profile_face.png” name=”のっくん”]バックスラッシュは、macだと「option」+「¥」で入力できるよ。[/speech_bubble]
最初に「r」がついてるのは、バックスラッシュがエスケープ文字として判定されるのを防ぐためです。raw文字列と呼ばれます。
これを踏まえて、コードを書くと以下のようになります。
import scrapy
from ..items import Headline
class NewsSpider(scrapy.Spider):
name = 'news'
allowed_domains = ['news.yahoo.co.jp']
start_urls = ['http://news.yahoo.co.jp/']
def parse(self, response):
print(response.css('ul.toptopics_list a::attr("href")').extract())
for url in response.css('ul.toptopics_list a::attr("href")').re(r'/pickup/\d+$'):
# url を urljoin() で絶対パスに変換
abs_url = response.urljoin(url)
yield scrapy.Request(abs_url, self.parse_topics)
def parse_topics(self, response):
item = Headline()
item['title'] = response.css('.newsTitle ::text').extract_first()
item['body'] = response.css('.hbody ::text').extract_first()
yield item
reで切り取ったurlは”/pickup/6306069″になりますので、urljoinでドメインをつけてフルパス”https://news.yahoo.co.jp/pickup/6306069″にしています。
parse_topicsでは各記事のタイトルと内容を取得しています。ここでもCSSセレクタが使われていますね。
Chromeの開発者ツールでタグを見てみましょう。
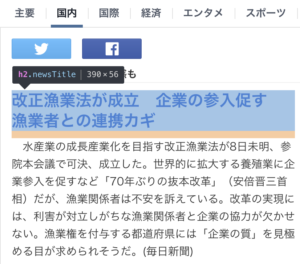

newsTitleとhbodyを指定すれば良いことがわかりました。::textが無いとタグも一緒に集めてきてしまうので指定しましょう。
クローリングした結果はJson Lines(.jl)形式で保存します。
(scraping) bash-3.2$ scrapy crawl news -o news.jl
(scraping) bash-3.2$ cat news.jl | jq .
{
"title": "改正入管法 「介護分野で最大6万人」 政府の期待に冷ややかな見方",
"body": " 8日成立した改正入管法で新設される在留資格「特定技能」によって、「介護分野に5年間で最大6万人」とする政府の受け入れ見込み数に対し、事業者から冷ややかな見方が出ている。既存の在留資格で受け入れた外国人介護職は10年で5000人にも満たない。背景には言葉の壁に加え、国際的な人材獲得競争の激化もある。(毎日新聞)"
}
catでファイルの内容を表示します。その際に日本語がエスケープされてしまいますが、jqコマンドを使うと日本語が見れます。
参考
「Python クローリング&スクレイピング」
以上です。お疲れ様でした。