
2018年のプレミアリーグは、マンチェスタシティが優勝、リバプールが2位、3位がチェルシーでした。
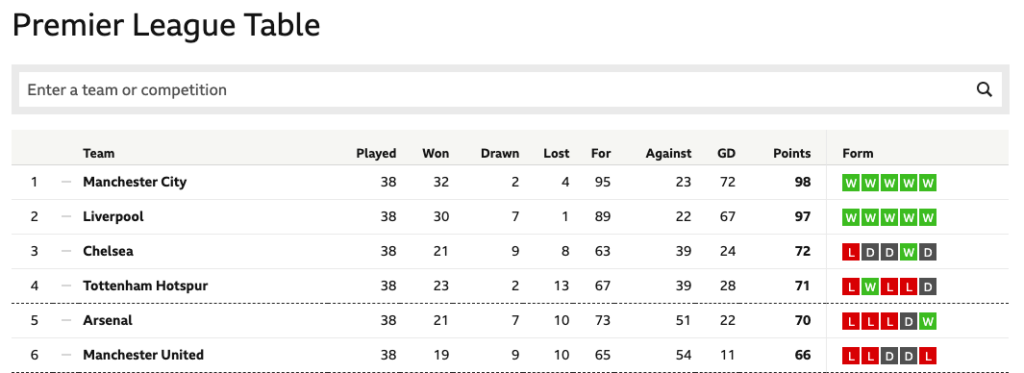
https://www.bbc.co.uk/sport/football/premier-league/table
今日はPandasを使ってこのランキング表を取得してみたいと思います。
ランキング表のスクレイピング(read_html)
pandasは既に入っているとして、追加で以下のパッケージをダウンロードします。
conda install -c anaconda lxml
Pandasの`read_html()`を使うと、tableタグ内のテーブルを取得できます。
import pandas as pd
prem_table_list = pd.read_html('https://www.bbc.co.uk/sport/football/premier-league/table')
この返り値はテーブルの中身が入ったリストです。
print(type(prem_table_list)) print(len(prem_table_list))
<class 'list'> 1
長さが1なので、最初の要素をデータフレームとして取り出します。
df = prem_table_list[0]
df.head()
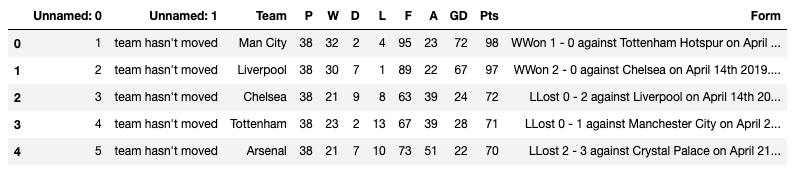
必要のないデータの削除(drop)
最初の2つのカラムが必要ないので、消します。
df.drop(df.columns[:2],inplace=True,axis=1) df.head()
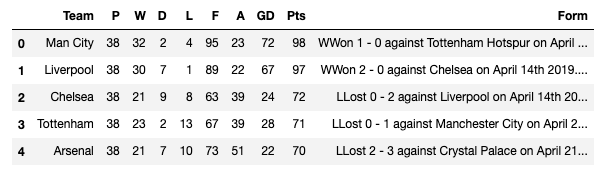
データの末尾を見てみると、
df.tail()
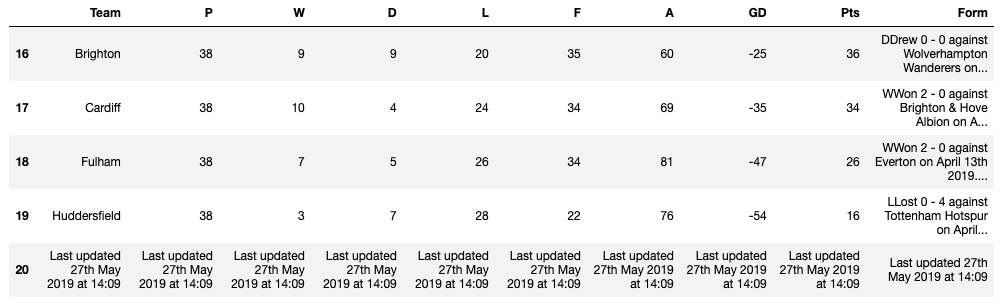
関係のないランキングのアップデート情報がありました。これは必要ないので消します。
20行目と、ついでにFormカラムを消します。
df.drop(df.index[20],axis=0,inplace=True) df.drop(["Form"],axis=1,inplace=True)
データタイプを数値に変換(to_numeric)
さて、ここで下準備が整ったので、分析していきたいと思います。
分析するには、カラムのデータタイプが数値である必要があります。
各カラムのデータタイプを確認してみます。
df.dtypes
Team object P object W object D object L object F object A object GD object Pts object dtype: object
なんとオブジェクトになっています。これは文字列(String)ということなので、数値にしないと計算ができません。
こういう時は、`to_numeric`を適用します。
errors=”coerce”を指定すると、数値に変換できなかった時にはNaNに変換してくれます。
df[["P","W","D","L","F","A","GD","Pts"]] = df[["P","W","D","L","F","A","GD","Pts"]].apply(pd.to_numeric,errors="coerce")
Team object P int64 W int64 D int64 L int64 F int64 A int64 GD int64 Pts int64 dtype: object
int64に変換ができました。
列名の変更(rename)
ここで1つ問題があります。列名が省略された文字なのでなんの事だかわかりません。
分かるように列名を変更しましょう。
inplace=Trueを指定すると、データフレームに変更が反映されます。
#カラム名の変更
df.rename(index=str, columns={"P": "Play", "W": "Win","D":"Draw","L":"Lose","F":"For"
,"A":"Against"},inplace=True)
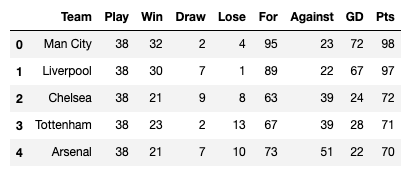
Playは試合数、Winは勝利数、Drawは引き分けの数、Loseは負けの数、Forは得点数の合計、Againstは失点数の合計、GD(Goal Difference)は得失点差です。Ptsは勝ち点ですね。
試しに1試合あたりの得点数と失点数を計算し、新しい列を追加してみます。
失点は英語で”Conceded”というらしいです。
df["Goal/Game"] = round(df["For"]/df["Play"],1) df["Conceded Goal/Game"] = round(df["Against"]/df["Play"],1)
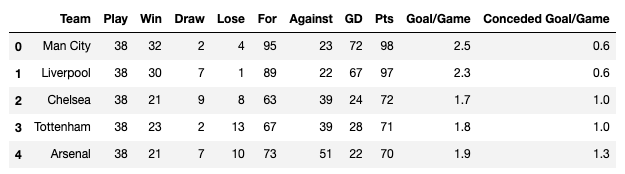
こんな感じで右側に2つのカラムを追加できました。
マンチェスターシティとリバプールは1試合あたりの得点が多いし、失点も少ないですね。
カラムのソート(sort_values)
1試合あたりの得点が多い順に並べてみましょう。
df.sort_values("Goal/Game",ascending=False)
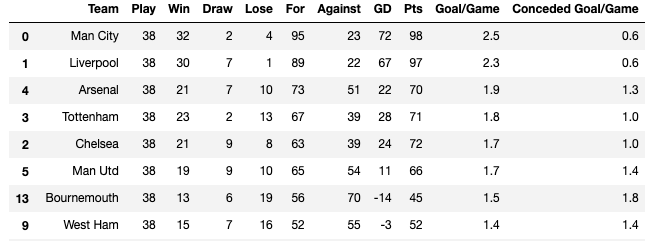
Pandasを使うと、このようにスクレイピング+データ分析ができます。
おわり。





