こんにちは。のっくんです。
今日は機械学習のk-NNアルゴリズムを理解してみようと思います。
k-NNとは簡単に言うと、最近傍、つまりもっとも近い点をk個探す方式です。そして、新しいデータがある時は多数決をとって近くに多くある方のクラスに分類します。
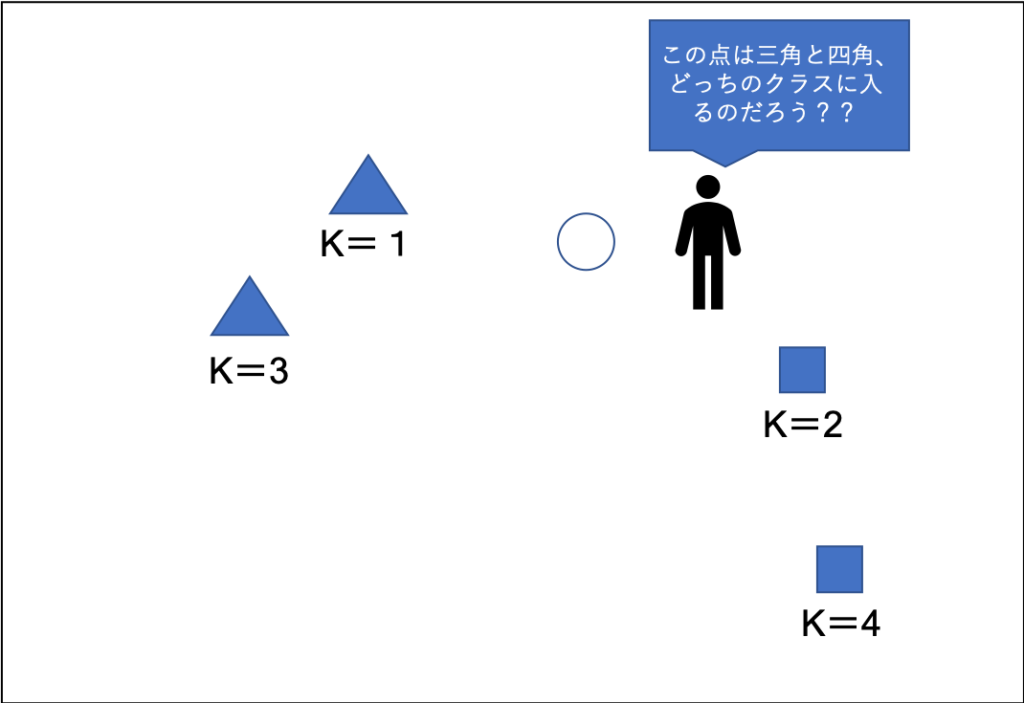
この例でいうと、
- kが1の時は三角が1番近いので新しい点は三角に分類されます。
- kが3の時は三角が2個、四角が1個なので三角に分類されます。
kは奇数にすることが推奨されています。なぜかと言うと、例えば、kが2で三角が1個、四角が1個の場合に、どちらにも分類できなくなってしまうからですね。
コードを書いて理解してみましょう。
やりたいことは以下の通り。
- 10個のデータとラベルをランダムに作る。
- ラベルの値によって、青チームと赤チームに分類する。
- 新しい点(new_comer)をランダムに作り可視化する。
- k-nn法を使って新しい点が青チームか赤チームどちらに分類されるか試してみる。
順番に書いていきましょう。
データとラベルを生成
import numpy as np
import matplotlib.pyplot as plt
import cv2
#乱数シードを固定
np.random.seed(42)
#枠線を表示
plt.style.use('ggplot')
# 座標(x,y)を持つ配列データを作成する
def rand_gen(sample):
data = np.random.randint(0,100,size=(sample,2))
label = np.random.randint(0,2,size=(sample))
return data.astype(np.float32),label
# 10個の座標(x,y)を持つ配列データを作成する
data,label = rand_gen(10)
データは0-100、ラベルは0-1の範囲で設定しています。
データは32bitの浮動小数点にしています。opencvで処理する時のためのルールです。
青チームと赤チームに分類
# 1は赤、0は青とする red = data[label.ravel() == 1] blue = data[label.ravel() == 0]
numpyのravel()を使って値を指定するとそのデータのみを取得することができます。
ラベルが1であれば赤チーム、0であれば青チームとしましょう。
新しい点を作り可視化
新しい点は先ほど作った関数で作成します。k-nnでクラスを予測するので、戻り値のラベルは破棄します。
可視化には、`matplotlib`を使います。
# 新しいデータを生成、ラベルは無視する new_comer, _ = rand_gen(1) # bはブルー、rはレッド、gはグリーン plt.plot(blue[:,0],blue[:,1],"bo") plt.plot(red[:,0],red[:,1],"ro") plt.plot(new_comer[0,0],new_comer[0,1],"go")
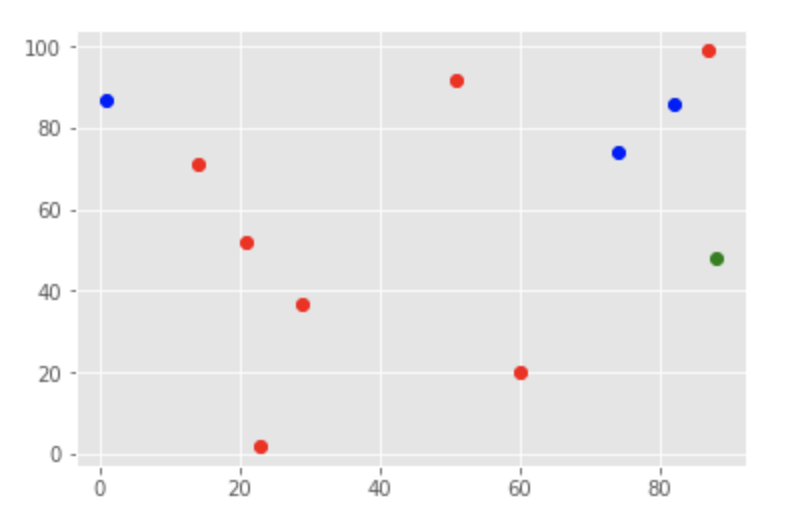
k-nnで分類
#学習する knn = cv2.ml.KNearest_create() knn.train(data,cv2.ml.ROW_SAMPLE,label) ret,result,neighbor,dist = knn.findNearest(new_comer,1) print(result,neighbor,dist) ret,result,neighbor,dist = knn.findNearest(new_comer,7) print(result,neighbor,dist)
k=1の時は、
[[ 0.]] [[ 0.]] [[ 872.]]
0、つまり青と分類されました。1番近い点が青だったからです。
k=7の時は、
[[ 1.]] [[ 0. 0. 1. 1. 1. 1. 1.]] [[ 872. 1480. 1568. 2602. 3305. 3602. 4505.]]
1、つまり赤と分類されました。7つの近傍点のラベルの多数決をとり、赤の方が多かったので赤となったわけです。
おわり。