
こんにちは。のっくん(@yamagablog)です。
前回の記事でファッション画像が含まれたデータベース、Fashion-MNISTの紹介をしました。
87%ほどの精度でしたので、もう少し精度を上げたいと思いチャレンジしてみました。
以下の2つの方法を使ったところ、精度向上ができました。
- 4層の畳み込みニューラルネットワーク
- データ拡張
[toc]
データの前処理
読み込んだ訓練用データ(X_train,y_train)を、さらに80%の訓練用画像と20%の検証用画像に分割します。
X_train, y_train = mnist_reader.load_mnist('../data/fashion', kind='train')
X_test, y_test = mnist_reader.load_mnist('../data/fashion', kind='t10k')
# (80%) を訓練用データに、(20%)を検証用データとして使う
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=13)
次に画像データが(784)のint型(整数型)で読み込まれているので、
- (28,28)の二次元配列に変換
- 画素値を255で割って0〜1の範囲のfloat(浮動小数点数)に変換
をします。
# Each image's dimension is 28 x 28
img_rows, img_cols = 28, 28
input_shape = (img_rows, img_cols, 1)
# Prepare the training images
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_train = X_train.astype('float32')
X_train /= 255
# Prepare the test images
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
X_test = X_test.astype('float32')
X_test /= 255
# Prepare the validation images
X_val = X_val.reshape(X_val.shape[0], img_rows, img_cols, 1)
X_val = X_val.astype('float32')
X_val /= 255
次にラベルデータも0-9の数字ではそのまま使えないので、ワンホットベクトルにします。
ワンホットベクトルというのは、例えば、
- 1 → [1,0,0,0,0,0,0,0,0,0]
- 2 → [0,1,0,0,0,0,0,0,0,0]
のように、カテゴリ数の要素を持つ1次元配列のことですね。
今回は、ファッションのカテゴリが10個あるので10としています。
kerasの`to_categorical`を使います。
num_classes = 10 y_train = keras.utils.to_categorical(y_train,num_classes) y_val = keras.utils.to_categorical(y_val,num_classes) y_test = keras.utils.to_categorical(y_test,num_classes)
学習
以下のような4層のCNNを作って学習します。
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D, BatchNormalization
cnn4 = Sequential()
cnn4.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
cnn4.add(BatchNormalization())
cnn4.add(Conv2D(32, kernel_size=(3, 3), activation='relu'))
cnn4.add(BatchNormalization())
cnn4.add(MaxPooling2D(pool_size=(2, 2)))
cnn4.add(Dropout(0.25))
cnn4.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
cnn4.add(BatchNormalization())
cnn4.add(Dropout(0.25))
cnn4.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
cnn4.add(BatchNormalization())
cnn4.add(MaxPooling2D(pool_size=(2, 2)))
cnn4.add(Dropout(0.25))
cnn4.add(Flatten())
cnn4.add(Dense(512, activation='relu'))
cnn4.add(BatchNormalization())
cnn4.add(Dropout(0.5))
cnn4.add(Dense(128, activation='relu'))
cnn4.add(BatchNormalization())
cnn4.add(Dropout(0.5))
cnn4.add(Dense(10, activation='softmax'))
cnn4.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adam(),
metrics=['accuracy'])
テストデータでの評価結果は以下の通り。
Test loss: 0.23880036748051645 Test accuracy: 0.9118
90%超えましたね。
次に、データ拡張をしてみました。データ拡張というのが画像の水増しのことでして、以下の記事に詳しく書いてありますのでよかったらどうぞ。
【Keras】ImageDataGeneratorで画像の水増しをしてみた
以下のようにジェネレータを使うと、実行するのに時間がかかりますのでGPUを使うのがオススメです。
from keras.preprocessing.image import ImageDataGenerator
gen = ImageDataGenerator(rotation_range=8, width_shift_range=0.08, shear_range=0.3,
height_shift_range=0.08, zoom_range=0.08)
train_batches = gen.flow(X_train, y_train, batch_size=256)
val_batches = gen.flow(X_val, y_val, batch_size=256)
テストデータでの評価結果は以下の通り。
Test loss: 0.18289670552909373 Test accuracy: 0.9341
さらに精度が向上しました。Googleが提出したベンチマークでは93%なので、まぁそこそこ良い値なのではないでしょうか。
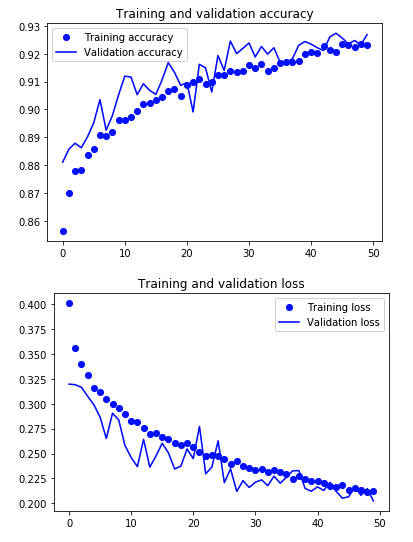
学習結果を可視化すると以下のようになりました。
考察
いつもならここで終わりなのですが、今回はもう少し踏み込んだ考察をしてみます。
機械学習には`classification_report`という便利な機能があり、これを使うとテストの段階で機械がどのカテゴリに分類したかをみることが出来ます。
# 予測したラベルを取り出す
predicted_classes = cnn4.predict_classes(X_test)
_, y_true = mnist_reader.load_mnist('../data/fashion', kind='t10k')
correct = np.nonzero(predicted_classes==y_true)[0]
incorrect = np.nonzero(predicted_classes!=y_true)[0]
from sklearn.metrics import classification_report
target_names = ["Class {}".format(i) for i in range(10)]
print(classification_report(y_true, predicted_classes, target_names=target_names))
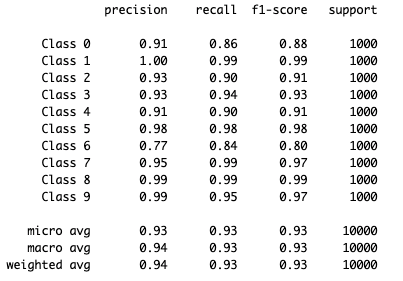
class6(シャツ)の正解率が低いですね。(recallとf1-scoreって何やねん。)
試しに、不正解だった画像を見てみます。
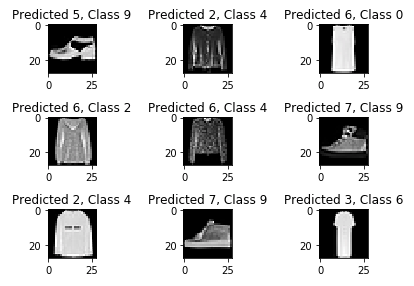
右下の6(シャツ)を3(ドレス)と判別し誤判定となっているようですが、私が見てもこれはシャツではなくドレスに見えます。
9(アンクルブーツ)を7(スニーカー)と判別して誤判定となっていますが、アンクルブーツとスニーカーの違いって人が見ても分かりづらいな〜って思います。
おわり。
参考
Medium,










