データ分析にはまっているのっくんです。
pandasを使ってデータ分析をしてみます。
映画の評価データを使ってユーザにオススメの映画を提案するコードを書いてみます。
映画データは以下のレポジトリのものを使用しました。
https://github.com/nishitjain/movie-recommendation-system-scratch
[toc]
使用する映画のデータ
使用するデータは以下の通り。
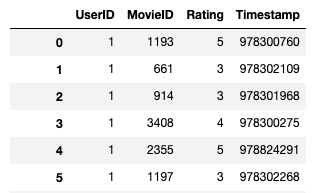
映画や映画に対する評価、ユーザIDなどからなる4列のデータだ。全部で100万行程あるが、私のMacBook Proでサクサク動きました。
ここでユーザ間の類似スコアを求めてみます。
ユーザ間の類似スコアは、ユーザ1とユーザ2の映画の評価のユークリッド距離を算出することで求められます。
処理としては以下の通り。
- ユーザ1のみた映画のリストを取得
- ユーザ2のみた映画のリストを取得
- ユーザ1とユーザ2が見た共通の映画を取得
- 共通の映画のユーザ1とユーザ2のそれぞれの評価を取得する
- 2つの評価のユークリッド距離を計算する
ユークリッド距離っていうのは、2つのリストの距離のこと。
例えば、ユーザ1の見た3つの映画の評価が[4,3,5]、ユーザ2が[3,4,6]だった場合、引算して二乗した値の総和の平方根をとれば良い。
ユークリッド距離 = √(4-3)^2+(3-4)^2+(5-6)^2
では順番に解説していきます。
観た映画のリストを取得
観た映画リストを取得する。`to_list()`を使うとSeriesをリストにして取得できる。
def get_movies(userid):
movies=[]
tmp = df_rating[df_rating.UserID == userid]
return tmp.MovieID.to_list()
映画の評価を取得する関数も作る。
def get_rating(userid,movieid):
#複数条件にするにはカッコが必要、useridとmovieidの一致した行を取得,返り値はデータフレーム
df_tmp = df_rating[(df_rating.UserID == userid) & (df_rating.MovieID == movieid)]
#取得した行のインデックスが0ではないため、リセットする
df_tmp = df_tmp.reset_index()
# 0行目、Rating列を指定する
return df_tmp.loc[0,'Rating']
最初、useridとmovieidが一致したデータフレームのインデックスを`reset_index()`でリセットしなかったため、0番目の行を指定するとエラーがでた。
ユークリッド距離の計算
2つのリストから共通の項目を取り出すにはset型に変換してから積集合をとれば良い。
import math
def similarily_score(user1,user2):
movies1 = get_movies(user1)
movies2 = get_movies(user2)
# リスト同士を比較して、共通の映画を取り出す
both_movies = set(movies1) & set(movies2)
rating1=[]
rating2=[]
for m in both_movies:
rating1.append(get_rating(user1,m))
rating2.append(get_rating(user2,m))
# ユークリッド距離を算出
distance = math.sqrt(sum([(a - b) ** 2 for a, b in zip(rating1, rating2)]))
# ユークリッド距離の逆数をスコアとする。0除算防止のため+1をする。
score = 1/(distance+1)
return score
user1 = 1
user2 = 310
print(similarily_score(user1,user2))
参考記事のコードよりはスッキリしたコードになっていることは間違いない。
おわり。
参考
building-a-movie-recommendation-engine-using-pandas:
https://towardsdatascience.com/building-a-movie-recommendation-engine-using-pandas-e0a105ed6762
Python Math: Compute Euclidean distance:
https://www.w3resource.com/python-exercises/math/python-math-exercise-79.php
How can I compare two lists in python and return matches:
https://stackoverflow.com/questions/1388818/how-can-i-compare-two-lists-in-python-and-return-matches