
こんにちは、のっくんです。
今日はプレミアリーグの各年度の移籍金をPythonでスクレイピングしグラフ化してみました。
プレミアリーグはイングランドにおける1部リーグでサッカーの頂点といえばプレミアリーグといっても過言ではありません。
岡崎のいるレスターシティや、アーセナル、リヴァプール、マンチェスターユナイテッドなど誰でも一度は聞いたことがあるチームが多数いるリーグです。
ブンデスリーガ、リーガエスパニョーラなどとともに五大プロサッカーリーグを形成しています。
この世界有数のリーグに毎年どの程度の移籍金が流れているか気になったので調べてみようと思います。
[toc]移籍金のデータ
移籍金のデータについては、以下のサイトに掲載されています。
トランスファーマーケットというサイトで、毎年の選手の移籍金の情報が掲載されています。
URLのsaison_idに年を指定することで、その年度のデータが表示されるようになっています。
*ただし、海外のサイトなので若干重いです。
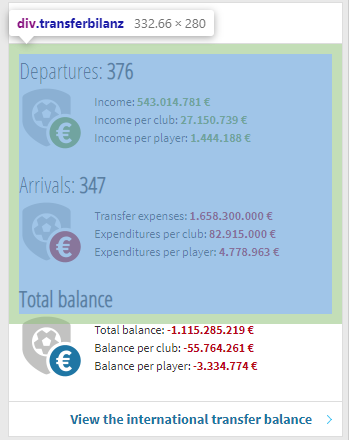
2018年のデータのTransfer Activity(移籍活動)、Departure(立ち去り)を見てみると、
- Income: 543.014.781 €
- Income per club: 27.150.739 €
- Income per player: 1.444.188 €
移籍金の収入が約5.4億ユーロ、1クラブ当たりの移籍金が約2700万ユーロとなっております。
流石、プレミアリーグですね。
1ユーロ120円などして、移籍金だけで約600億円の収入があるようです。
これにテレビ放映権料やスタジアム収入などを加えればさらに額は増えます。
欧州の主要リーグの中でも、プレミアリーグは圧倒的な売上高を誇っているようです。
選手が立ち去り、つまり他のリーグにいくことでプレミアリーグとしては移籍金が入ってくるのでその移籍金の合計額、1チーム当たりの移籍金、1選手あたりの移籍金が掲載されています。
Requestsを使ってURLにアクセス
requestsを使って、URLにアクセスします。
URLですが、年齢の部分は可変に指定できるようにyear変数として扱うようにします。
For文で指定した年(startからendまで)のデータを取得します。
うまくアクセスできていればステータスコードで200番が返ってきます。ちなみにこのサイトにUser-Agentを指定せずにアクセスしたら404が返ってきたので適当に指定する必要があります。
for year in range(start,end):
# URLの中に年を指定することで、その年のプレミアリーグの収入を取得します。
print(year)
url="https://www.transfermarkt.com/premier-league/transfers/wettbewerb/GB1/plus/?saison_id="+str(year)+"&s_w=&leihe=0&leihe=1&intern=0&intern=1"
# requestsを使って、HTMLの情報を取得する
# getの時にヘッダーをつけないと404が返ってくるよ
response = requests.get(url,headers={'User-Agent': 'hoge'})
# ステータスコードを確認(200なら問題なし)
print(response.status_code)
BeautifulSoupを使って情報を取り出す
次にrequestsで取得したデータをBeautifulSoupに渡します。テキスト情報として渡さないとエラーが返ってくるので注意です。
検証ツールを使って、移籍金が記載されているタグやクラス名を指定します。
Findでは1つのタグ、find_allでは該当するすべてのタグを取得できます。
Findでは、画像の例にあるようにdivタグのtransferbilanzクラスを指定します。

Find_allでは、spanタグのgreentextクラスを指定しています。grenntextクラスが記載されたタグは、Income(移籍金)、Income per club(1チーム当たりの移籍金)、income per player(1選手当たりの移籍金)の3つがありますので、find_allを使ってすべて取得します。
# BeautifulSoupにHTMLの内容を渡す。htmlパーサを指定するのが定石。
# テキスト情報に変換してBeatifulSoupに渡さないとエラーが返ってくる
soup = BeautifulSoup(response.text,"html.parser")
# 収支の情報が格納されているdivタグを指定する
premier = soup.find('div', {'class':'transferbilanz'})
# 収入の情報が格納されているdivタグを指定する
money = premier.find_all('span', {'class':'greentext'})
必要な情報のみを取り出す
これはかなり細かいことですが、移籍金に「.」や「€」などのいらない情報があるのでこれを削除して、数値データとしてリストに追加していきます。appendはリストにデータを追加するメソッドです。
# 3つの収入が取得できるので、リストのインデックスを指定してそれぞれの情報を取り出す。
# rstripは右から指定した文字列を削除する
# replaceを使って文字列中の不要な文字列を削除する
# 文字列として扱っているので、floatとしてリストに追加するようにする
income.append(float(money[0].text.rstrip(" €").replace(".","")))
income_per_team.append(float(money[1].text.rstrip(" €").replace(".","")))
income_per_player.append(float(money[2].text.rstrip(" €").replace(".","")))
スクレイピングするコード
コード全体は以下の通りです。
関数の引数には、開始年度と終了年度を指定します。
実行すると、スクレイピングした移籍金の3つの情報が返ってきます。
import requests
from bs4 import BeautifulSoup
# プレミアリーグの移籍金情報をスクレピングする。
# 移籍金を取得したい開始年度、終了年度を指定する。
# 終了年度は含まれない。2019を指定した場合は、2018年まで。
def scrapePremiurLeague(start,end):
# 収入、1チーム当たりの収入、1選手当たりの収入を入れるためのリストを宣言します。
income=[]
income_per_team=[]
income_per_player=[]
for year in range(start,end):
# URLの中に年を指定することで、その年のプレミアリーグの収入を取得します。
print(year)
url = "https://www.transfermarkt.com/premier-league/transfers/wettbewerb/GB1/plus/?saison_id="+ str(year) +"&s_w=&leihe=0&leihe=1&intern=0&intern=1"
# requestsを使って、HTMLの情報を取得する
# getの時にヘッダーをつけないと404が返ってくるよ
response = requests.get(url,headers={'User-Agent': 'hoge'})
# ステータスコードを確認(200なら問題なし)
print(response.status_code)
# BeautifulSoupにHTMLの内容を渡す。htmlパーサを指定するのが定石。
# テキスト情報に変換してBeatifulSoupに渡さないとエラーが返ってくる
soup = BeautifulSoup(response.text,"html.parser")
# 収支の情報が格納されているdivタグを指定する
premier = soup.find('div', {'class':'transferbilanz'})
# print(premier)
# 収入の情報が格納されているdivタグを指定する
money = premier.find_all('span', {'class':'greentext'})
# print(money)
# 3つの収入が取得できるので、リストのインデックスを指定してそれぞれの情報を取り出す。
# rstripは右から指定した文字列を削除する
# replaceを使って文字列中の不要な文字列を削除する
# 文字列として扱っているので、floatとしてリストに追加するようにする
income.append(float(money[0].text.rstrip(" €").replace(".","")))
income_per_team.append(float(money[1].text.rstrip(" €").replace(".","")))
income_per_player.append(float(money[2].text.rstrip(" €").replace(".","")))
return income,income_per_team,income_per_player
リストからデータフレームに変換
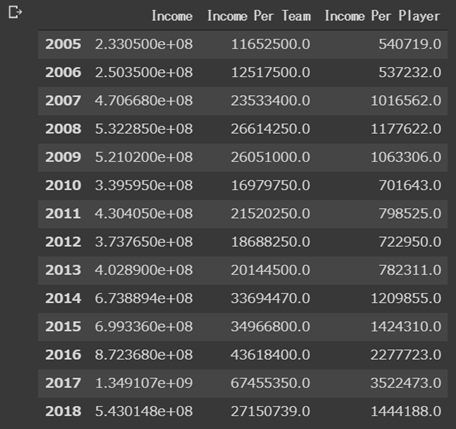
試しに2005年から2019年の間のデータを取得してみます。
リストで移籍金の情報が取得したら、列名を指定してpandasのデータフレームに変換します。
a,b,c = scrapePremiurLeague(2005,2019)
import pandas as pd
# リストからデータフレームを作成する
df = pd.DataFrame({'Income':a , 'Income Per Team':b, 'Income Per Player':c},index=range(2005,2019))
df
データフレームの出力です。
棒グラフにして出力する
Pandasには棒グラフにして出力する機能があるのでそれを使います。
df["Income"].plot.bar()
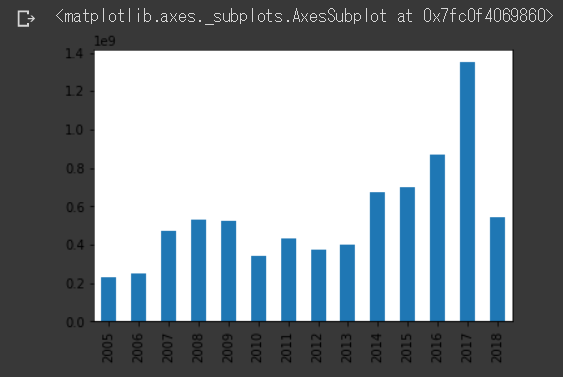
すいません、Google Colabの背景が黒なので見にくいですが、縦が金額(十億ユーロ)、横軸が年度です。
2018年は約5億ユーロですが、2017年は約14億ユーロもあったみたいですね。2017年は大物プレーヤーがプレミアリーグから外に移籍したことが予測できます。
おわり。






