こんにちは、のっくんです。
前回の記事に引き続き、ディープラーニングで猫と犬の画像の判別にトライしてみたいと思います。
前回の記事はこちら:
今回は、データの水増しをしてから学習してみたいと思います。
[toc]
データの水増しとは
データの水増しでは、一枚の画像から類似画像を複数生成します。
詳しくは以下の記事にまとめてありますのでよかったらどうぞ。
【Keras】ImageDataGeneratorで画像の水増しをしてみた
以下のコードで、水増しした画像をみてみましょう。
コードの流れは以下の通り。
- 訓練用のディレクトリから画像を1枚、150×150のサイズで読み込む。
- 水増し用の関数、ImageDataGeneratorで水増しする
- 生成した画像をmatplotlibに貼り付けて表示する
注意点としては、ジェネレータは無限に画像を生成できてしまうことです。
無限ループになるので、今回はfor文で繰り返す回数を4に指定して4枚だけ生成するようにしています。
base_dir = "/home/matsu/cats_and_dogs_small"
train_dir = os.path.join(base_dir,'train')
train_cats_dir = os.path.join(train_dir,'cats')
# ファイルパスを取得
fnames = [os.path.join(train_cats_dir,fname) for fname in os.listdir(train_cats_dir)]
#適当な画像を選択
img_path = fnames[2]
img = load_img(img_path,target_size=(150,150))
x = img_to_array(img)
x = x.reshape((1,) + x.shape)
datagen = ImageDataGenerator(rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode="nearest")
# xは1サンプルのみなのでbatch_sizeは1で固定
g = datagen.flow(x, batch_size=1)
for i in range(4):
batches = g.next()
plt.figure(i)
# 4次元から3次元データにし、配列から画像にする。
gen_img = array_to_img(batches[0])
plt.imshow(gen_img)
plt.show()

元は同じ画像ですが、左右上下に反転したり平行移動しているので、それぞれ違う画像に見えます。
元画像は一枚でも、類似画像を作成してくれる機能がKerasにはあります。すごいですね。
データ集めの時に色んな角度、位置から撮る必要がなくて良いです。
ディープラーニングをする
それでは、本題のディープラーニングに入っていきます。
主な流れは以下の通り。
- 訓練用と検証用の画像を読み込む(訓練用画像は水増しする)
- 学習する
- 学習した過程を可視化する
では順番に見ていきます。
訓練用と検証用の画像を読み込む(訓練用画像は水増しする)
from keras.preprocessing.image import ImageDataGenerator
import os
from keras import layers
from keras import models
from keras import optimizers
base_dir = "/home/matsu/cats_and_dogs_small"
train_dir = os.path.join(base_dir,'train')
validation_dir = os.path.join(base_dir,'validation')
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode="nearest")
validation_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150,150),
batch_size=32,
class_mode="binary"
)
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
target_size=(150,150),
batch_size=32,
class_mode="binary"
)
バッチサイズを32にしています。前回のバッチサイズは20でしたが、水増しによって枚数が増えたので一度に処理できる数を増やしています。
水増しするのは訓練画像だけであることに注意してください。
学習する
前回と同様にモデルを作って学習していきます。
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation="relu"))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation="relu"))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation="relu"))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512,activation="relu"))
model.add(layers.Dense(1,activation="sigmoid"))
model.compile(loss="binary_crossentropy",
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=["acc"])
history = model.fit_generator(train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
model.save("cats_and_dogs_small_2.h5")
前回と違うのは、過学習を防ぐためにドロップアウト層を追加していることです。
あとは、学習時のステップ数を100としています。バッチサイズが32でステップが100なので、1エポックあたり3200枚が学習に使われます。
元画像が2000枚なので、1200枚が水増しされた計算ですかね。
それを100エポック繰り返すようにしています。かなり時間がかかるのでGPUで処理した方が良いですね。
検証用のパラメータは水増ししていないので、前回と同様です。
私の環境ではGeforceのGTX1060を使って、40分程かかりました。
学習した過程を可視化する
学習した過程を可視化して見ます。
import matplotlib.pyplot as plt %matplotlib inline acc = history.history["acc"] val_acc = history.history["val_acc"] loss = history.history["loss"] val_loss = history.history["val_loss"] epochs = range(1,len(acc) + 1) plt.plot(epochs, acc,"bo",label="Training Acc") plt.plot(epochs, val_acc,"b",label="Validation Acc") plt.legend() plt.figure() plt.plot(epochs,loss,"bo",label="Training Loss") plt.plot(epochs,val_loss,"b",label="Validation Loss") plt.legend() plt.show()
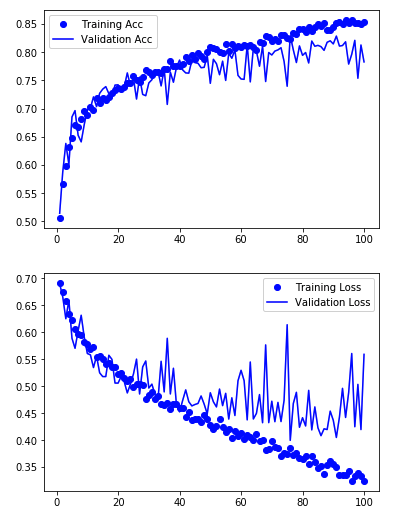
バリデーションの正解率が最高で82.93 %でした。
前回の記事の結果(水増しがない場合)だと74.40 % でしたのでそこそこ精度が向上したようです。
おわり。
次の記事:
前の記事: