こんにちは、のっくんです。
最近はもっぱらディープラーニングにはまっています。
前回、前々回に引き続き犬と猫の画像判別をやってみます。
だんだん精度は良くなってきていますが、まだまだ良くなる余地があります。
今回は、既存モデルを使った特徴量抽出をやってみたいと思います。
[toc]
特徴量の抽出とは
特徴量抽出には、ディープラーニングでは有名なVGG16を使います。
このモデルは画像に何が映っているか判別するためのモデルです。1000クラスの画像分類ができます。
前の記事でその性能を試してみました。
モデルを読み込んで、画像を入れただけですが、犬、猫、ゾウを正しく判別しました。
ディープラーニングってすげえ。
今回はこのモデルで特徴を抽出して、特徴量を入力として学習します。
既存の優秀なモデルがあるのであれば、1から学習するよりも精度がでる予感がします。
学習済みモデルは畳み込みベースとも呼ばれます。
畳み込みベースを使った特徴抽出の方法は2つあります。
- 畳み込みベースを使って特徴量を抽出し配列に保存。それを全結合分類器の入力として使う。
- 畳み込みベースを拡張して新しいモデルを作り訓練する。
1の方法は処理が軽いですが、水増しができません。2は重いですが、水増しが可能です。
この記事では1の方法をやっていきます。
インポート
from keras.applications import VGG16 import os import numpy as np from keras.preprocessing.image import ImageDataGenerator from keras import models from keras import layers from keras import optimizers base_dir = "/home/matsu/cats_and_dogs_small" train_dir = os.path.join(base_dir,'train') validation_dir = os.path.join(base_dir,'validation')
モデルの読み込み
学習済みのモデル(畳み込みベース)を読み込みます。
# weightsは重みのチェックポイント。include_topは全結合層を含めるかどうか。imagenetの1000クラス分類に対応。
conv_base = VGG16(weights = "imagenet",
include_top=False,
input_shape=(150,150,3))
conv_base.summary()
1000クラスに分類するための全結合層は必要ないので、include_topはFalseにしています。
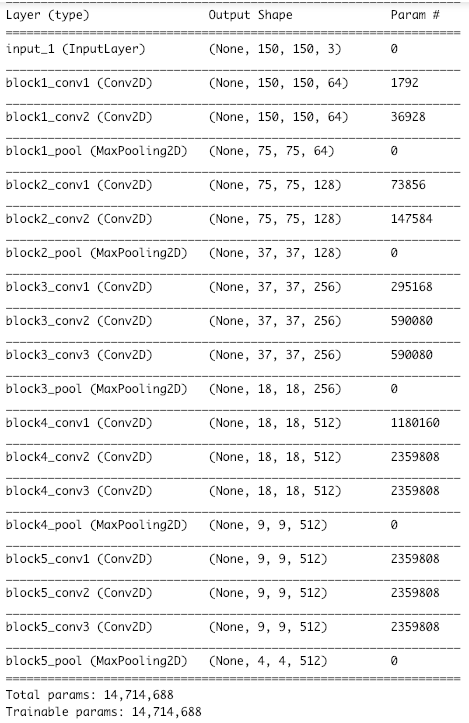
(150,150)の画像を入力として、特徴量の出力は(4,4,512)の形です。この形と同じnumpyの配列を用意して、そこに特徴量を保存して行くことにします。
特徴量の抽出
さてここからが本番です。
特徴量を抽出するのに、以下のステップに従いコードを書いていきます。
- 特徴量とラベルを格納するnumpy配列の初期化
- ジェネレータの初期化
- ジェネレータを回し、画像とラベルを取得(この時に無限ループしないようにループ回数を指定)
- 画像から特徴量を抽出しnumpy配列に格納
- 特徴量はそのまま全結合層にインプットするため平坦化する
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
def extract_features(directory,sample_count):
# 画像の特徴量とラベルを入れるnumpyの配列を用意する
# 配列のサイズはVGG16モデルの出力と合わせる
features = np.zeros(shape=(sample_count,4,4,512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(directory,
target_size=(150,150),
batch_size=batch_size,
class_mode="binary")
loop = int(sample_count/batch_size)
print(loop)
for i in range(loop):
#ジェネレータから20個の画像データとラベルを取得
data_batch,label_batch = generator.next()
#VGG16のモデルを使って、(4,4,512)の特徴を抽出
features_batch = conv_base.predict(data_batch)
# 20個ずつ特徴量とラベルを詰めていく
start = i * batch_size
end = (i+1) * batch_size
print(start,end)
features[start : end] = features_batch
labels[start : end] = label_batch
return features,labels
train_features,train_label = extract_features(train_dir,2000)
validation_features,validation_label = extract_features(validation_dir,1000)
train_features = np.reshape(train_features ,(2000, 4 * 4 * 512))
validation_features = np.reshape(validation_features ,(1000, 4 * 4 * 512))
学習
得られた特徴量を全結合層の入力として学習させてみます。
model = models.Sequential()
model.add(layers.Dense(256, activation="relu", input_dim = 4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1,activation="sigmoid"))
model.compile(optimizer=optimizers.RMSprop(lr=2e-5),
loss="binary_crossentropy",
metrics=['acc'])
history = model.fit(train_features,train_label,
epochs=30,
batch_size=20,
validation_data=(validation_features,validation_label))
可視化
import matplotlib.pyplot as plt %matplotlib inline acc = history.history["acc"] val_acc = history.history["val_acc"] loss = history.history["loss"] val_loss = history.history["val_loss"] epochs = range(1,len(acc) + 1) plt.plot(epochs, acc,"bo",label="Training Acc") plt.plot(epochs, val_acc,"b",label="Validation Acc") plt.legend() plt.figure() plt.plot(epochs,loss,"bo",label="Training Loss") plt.plot(epochs,val_loss,"b",label="Validation Loss") plt.legend() plt.show()

バリデーションの正解率は最高で90.50%でした。
どんどん精度が上がっていって面白いですね。
ただ、訓練が進んでもバリデーションのロスが減っていっていません。水増ししていないので過学習が起きています。
次は、特徴量抽出+水増しにもチャレンジしたいと思います。
次回の記事:
前回の記事:
おわり。