
こんにちは。のっくんです。
前回の記事では特徴量抽出の方法を学びました。
今回はモデルの拡張とファインチューニングをしていきたいと思います。
[toc]
やりたいこと
今回は畳み込みベース(VGG16)にオリジナルの全結合分類器を接続して新しいカスタムネットワークを作り学習するようにします。(左の図)
この時に畳み込みベースは凍結、つまり学習によってパラメータ(重み)の更新を行わないようにします。
VGG16が壊れないようにして出力だけを利用する感じですね。
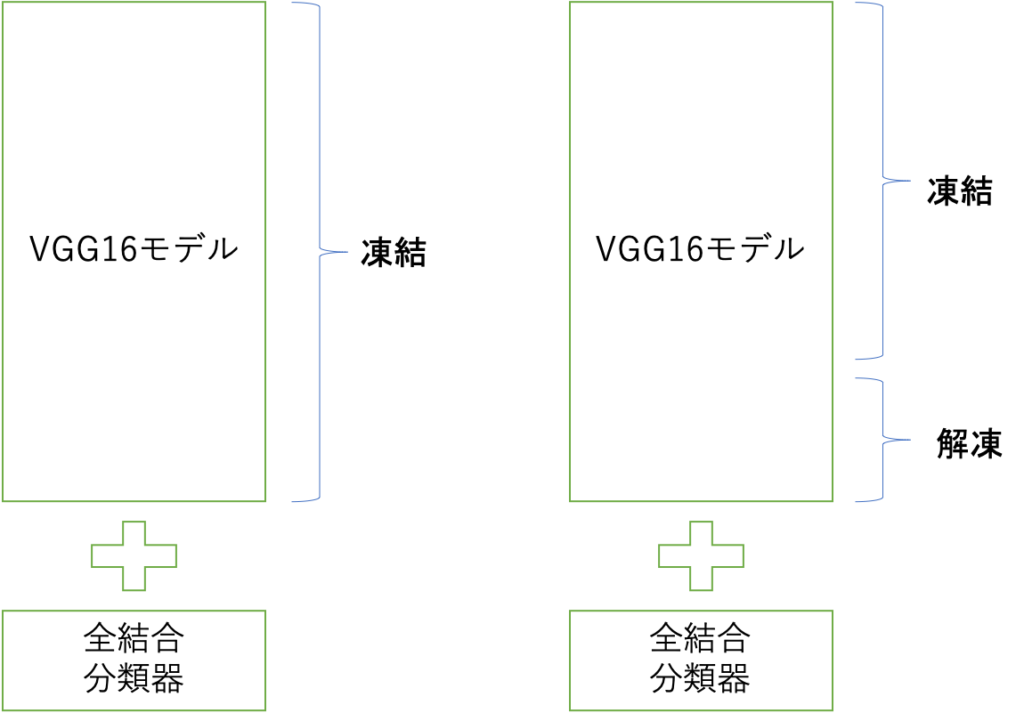
さらに畳み込みベースの一部を解凍して訓練することで精度の向上を狙います。これはファインチューニングと呼ばれる方法です。(右の図)
モデルを全部訓練するのはよろしくないので、一部だけ解凍します。
理由としては、
- パラメータ数が多いので学習するのは大変
- モデルの下の方がより具体的な特徴を含んでいて、そこをチューニングした方が精度が高まりやすい
とのこと。
モデルの拡張(VGG16+全結合分類器)
VGG16モデルをダウンロードして構造を出力します。
from keras.applications import VGG16
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras import models
from keras import layers
from keras import optimizers
# weightsは重みのチェックポイント。include_topは全結合層を含めるかどうか。imagenetの1000クラス分類に対応。
conv_base = VGG16(weights = "imagenet",
include_top=False,
input_shape=(150,150,3))
conv_base.summary()

19個のレイヤがあり、訓練可能なパラメータは1470万ほどあることが確認できます。
次に、全結合層を追加します。
model = models.Sequential() model.add(conv_base) model.add(layers.Flatten()) model.add(layers.Dense(256,activation='relu')) model.add(layers.Dense(1,activation='sigmoid')) model.summary()

出力を見ると、vgg16を含む全てのパラメータが訓練可能になっています。
畳み込みベースであるvgg16を凍結します。
conv_base.trainable = False model.summary()

vgg16のパラメータが訓練不可能になりました。
ジェネレータでデータを作っていきます。バリデーションデータは水増ししないこと、バッチサイズは20であることに注意です。
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
validation_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
validation_generator = validation_datagen.flow_from_directory(validation_dir,
target_size=(150,150),
batch_size=20,
class_mode='binary')
学習します。エポックは30です。
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['acc'])
history = model.fit_generator(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
学習過程を可視化します。
import matplotlib.pyplot as plt %matplotlib inline acc = history.history["acc"] val_acc = history.history["val_acc"] loss = history.history["loss"] val_loss = history.history["val_loss"] epochs = range(1,len(acc) + 1) plt.plot(epochs, acc,"bo",label="Training Acc") plt.plot(epochs, val_acc,"b",label="Validation Acc") plt.legend() plt.figure() plt.plot(epochs,loss,"bo",label="Training Loss") plt.plot(epochs,val_loss,"b",label="Validation Loss") plt.legend() plt.show()
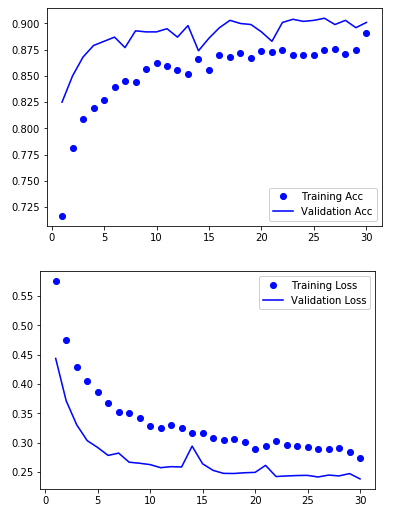
バリデーションの精度は90.50%でした。なかなか良い精度。
モデルのファインチューニング
畳み込みベースの一部を解凍して学習するファインチューニングをします。
再度VGG16のネットワークを表示してみます。
ここで19層あるうちのblock5_conv1からblock5_conv3までを訓練可能にします。
具体的には以下の通り。
- 一度全ての畳み込みベースを解凍し、訓練可能にする。
- 畳み込み層の5ブロック目より上を訓練不可能な状態にする。
- リストのスライスでは、0から始まり終点(15)を含まないことに注意。
- 学習率は低めに設定。
conv_base.trainable = True
for layer in conv_base.layers[:15]:
print(layer)
layer.trainable = False
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
こちらも可視化します。
acc = history.history["acc"] val_acc = history.history["val_acc"] loss = history.history["loss"] val_loss = history.history["val_loss"] epochs = range(1,len(acc) + 1) plt.plot(epochs, acc,"bo",label="Training Acc") plt.plot(epochs, val_acc,"b",label="Validation Acc") plt.legend() plt.figure() plt.plot(epochs,loss,"bo",label="Training Loss") plt.plot(epochs,val_loss,"b",label="Validation Loss") plt.legend() plt.show()
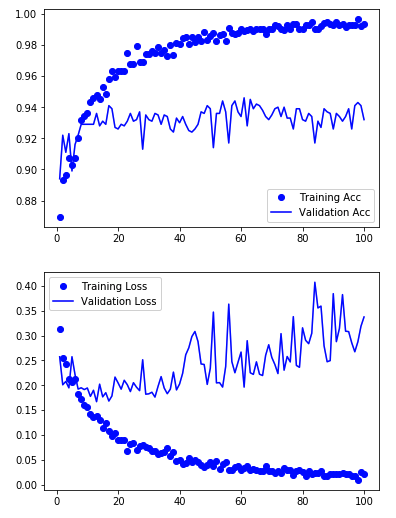
バリデーションの精度は94.40%で前回より向上しました!
おわり。
続きは以下の記事です。
【keras】InceptionResNetV2の転移学習【犬猫判別5】







