
こんにちは、のっくんです。
データ分析でPandasを使っていると、カラム名が異なる2つのデータフレームをマージしたいことがあります。
今日はその方法をご紹介します。
[toc]
例えば、以下のような郵便番号(zipcode)を持つ2つのデータフレームがあるとします。
import pandas as pd
df_orig = pd.DataFrame({'zipcode': [90000, 90001, 90002, 90003]})
df_store = pd.DataFrame({'store_name':["A cafe","B cafe","C cafe","D cafe","E cafe","F cafe"],'zip': [90000, 90001, 90001, 90001,90002,90002]})
郵便番号のマスターデータです。

こちらは、お店の名前と郵便番号のデータです。
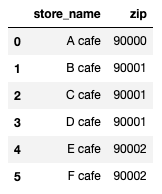
さて、ここで問題です。
「各郵便番号ごとにお店の数を求め、最初のデータフレームにマージして下さい。」
この問題を解くには以下の通りコードを書いていきます。
- カラム名を同じにする
- 郵便番号の数をカウントする
- マージする
データフレームのマージの大前提ですが、基準とするカラム名が同じでないとマージできません。
今回の場合は、マスターの郵便番号(zipcode)にお店の数をマージするということをやりたいので、2つ目のデータフレームのカラム名を1つ目と同じにします。
df_store.columns = ['store_name', 'zipcode']
そして、郵便番号が同じお店の数を数えます。こういう時はgroupbyと`count`を組み合わせて使います。
df_store_num = df_store.groupby("zipcode").count()
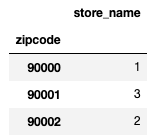
これで郵便番号ごとのお店の数がわかりました。
うまくいっていると思いきや、2つ問題があります。
何でしょうか。
- カラム名がお店の数になっていない
- zipcodeがインデックスになっているので、カラムにする必要がある
1つ目は、カラム名を変更するだけで良いですが、2つ目の問題に対処するには、`reset_index()`を使います。これを使うことでインデックスを振り直すことができるんです。
df_store_num.columns = ["zipcode","number_of_store"] df_store_num = df_store_num.reset_index()
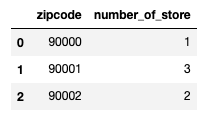
こんな感じ。
これで、マージするための準備が整いました。
データフレームのマージっていっても結構下準備が大変なんですね。
マージするには、基準カラムに郵便番号、結合方法に左結合を指定し、郵便番号のマスターデータにお店の数を追加します。
df_merged = pd.merge(df_orig,df_store_num,on="zipcode",how="left")
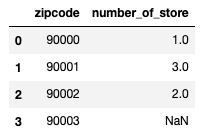
できました。3つ目の郵便番号にあるお店は存在しないので、欠損値になっています。
なぜ浮動小数点数になっているのかは不明ですが気にしないことにします。
おわり。









