今日はディープラーニングを使って、adidasとnikeの靴を判別してみたいと思います。
Adidasとnike。
違いはアディダスの3本の線と、ナイキのスラッシュですね。
そのマークが画像中にあるかないかで判別するAIを作成していきます。
必要な画像データは以下のgithubのサイトに公開されていました。
https://github.com/CShorten/NIKE_vs_ADIDAS.git
ナイキとアディダスの画像が70枚ずつ、合計140枚あります。
機械学習するには少量のデータセットですが、まぁ良いでしょう。
少量でないとダウンロードに時間がかかります。
データセットもgithubに公開されているのは珍しいです。
ちなみに、上記のサイトにはコードも記載されていましたが、読みづらく理解できなかったので、1から書いていくことにします。
まずは、画像を拝見。

左がアディダス、右がナイキです。
横が300,縦が200程度の横長のカラー画像です。
サイズがバラバラなので、どのサイズに統一すべきか迷います。
今回は、ナイキかアディダスのマークが映ってさえいればよいので、深く考えずに横120,縦120のサイズで読み込むことにしました。
このデータセット、TRAINとTESTにフォルダが分割されているのは良いのですが、その下にADIDASとNIKEでフォルダ分けされていないです。
画像ファイル名に、ADIDASとNIKEと記載されているので、ファイル名からラベルを判別するようにします。
手順としては、
- TRAINとTESTの下にある画像のファイル名を全て取得する
- ファイル名から画像を読み込む。サイズは120,120で読み込む。OpenCVで読み込む場合には、BGRからRGBに変換する必要あり。読み込んだ画像はXという名前のリストに追加していく。
- ファイル名にNIKEが含まれていれば1、含まれていなければ0のラベルとする。ラベルはyという名前のリストに追加していく。
- 訓練用とテスト用に分割する
- ネットワークを構築する
- 訓練画像で学習する
- テスト画像で精度評価する
まぁこんなかんじです。
TRAINとTESTフォルダに分かれていますが、フォルダ名に関係なくすべてのファイル名を一旦読み取り、画像とラベルのリストにそれぞれ追加していきます。
訓練用画像とテスト用画像の分割には、scikit-learnの分割する機能train_test_splitを使います。
多分、データセットを用意した人の意図としては、訓練:70枚、テスト:70枚を想定したと思いますが、通常テスト画像は2割程度なので、
- 140枚すべて読み込む
- Train_test_splitで、訓練:テスト=8:2の割合で分割する。訓練画像は112枚、テスト画像は28枚です。
ようにしました。
畳み込みネットワークには、4層の畳み込み層、2層の全結合層からなるネットワークを構築しました。
まぁ割とこの辺は適当でして、畳み込み層や全結合層の数はもっと増やしたり減らしたりしても面白いと思います。
学習結果は以下の通り。
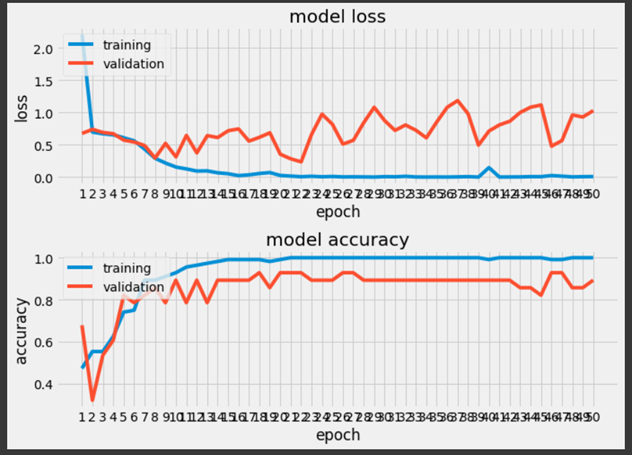
エポックが多いのでちょっと見づらいですが、ヴァリデーションの精度は9割程度でした。
テスト画像での評価結果は89.28%でした。
悪くないですね!
もうちょっと精度ほしいなと思い、いろいろ試してみました。
データ拡張やVGG16モデルの転移学習もしてみたのですが、精度は上がらず。(むしろ下がった)
VGG16の転移学習は一般的には有効ですが、今回のデータセットではあまり有効ではありませんでした。
コードは以下の通り。
import os
from os import walk
import cv2
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import numpy as np
from sklearn.model_selection import train_test_split
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
plt.figure(figsize=(10,8))
train_path = "NIKE_vs_ADIDAS/TRAIN/"
test_path = "NIKE_vs_ADIDAS/TEST/"
f = []
for (dirpath, dirnames, filenames) in walk(train_path):
f.extend(os.path.join(dirpath, filename) for filename in filenames)
for (dirpath, dirnames, filenames) in walk(test_path):
f.extend(os.path.join(dirpath, filename) for filename in filenames)
for i,d in enumerate(f[:10]):
print(i,d)
plt.subplot(5,2,i+1)
plt.imshow(mpimg.imread(d))
X = []
y = []
for i in f:
img = cv2.imread(i)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img,(120,120))
X.append(img)
file_name = i.split("/")[2]
if file_name.split("_")[0] == "NIKE":
y.append(0)
else:
y.append(1)
X = np.array(X)
y = np.array(y)
X_train, X_test,y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
height = 120
witdh = 120
num_classes = 2
in_shape = (witdh,height,3)
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=in_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = model.fit(X_train, y_train,
batch_size=32, epochs=50,
verbose=1,
validation_data=(X_test, y_test))
score = model.evaluate(X_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
おわり。