こんにちは、のっくんです。
今日はKaggleにあった以下のデータセットの分類にチャレンジしてみました。
https://www.kaggle.com/alxmamaev/flowers-recognition
データセットの中には、以下の五種類の花が含まれています。
- Daisy, ヒナギク
- Dandelion, たんぽぽ
- Rose, バラ
- Sunflower, ひまわり
- Tulip, チューリップ
最終的に100%の精度で分類できましたので、順番に内容を説明していきます。
ディープラーニングのフレームワークはkerasを使用しました。
[toc]データセットの読み込み
まずこのデータセットですが、花ごとに枚数がそれぞれバラバラなので、1番少ない700枚ずつ使用することにします。合計で3500枚(700枚×5)ですね。
X = []
y = []
for i in files:
img = cv2.imread(i)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img,(90,120))
X.append(img)
category = i.split("/")[2]
y.append(category)
X = np.array(X)
y = np.array(y)
データは、画像ですので、OpenCVを使って、読み込み、そのあとにBGRをRGBに変換しました。適当なサイズ縦90、横120にリサイズしました。その後、numpyの配列に変換します。
ラベルはフォルダ名から取得し、numpyの配列に変換します。Numpyのunique関数を使うときに、return_inverseをTrueにすると、文字列のラベルを数値に変換してくれます。
# (80%) を訓練用データに、(20%)をテスト用データとして使う X_train, X_test,y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) # さらに(80%) を訓練用データに、(20%)を検証用データとして使う X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=0)
次に、訓練データ、検証データ、テストデータを作っていきます。
Scikit-learnのtrain_test_splitを使って分割します。
最初に、訓練データとテストデータに、8対2の割合で分割します。
分割された訓練データを、さらに8対2の割合で、訓練データと検証データに分割します。
こうすることで、合計3500枚あったデータを以下のように分割しました。
- 訓練データ:2240枚
- 検証データ:560枚
- テストデータ:700枚
その後、データを浮動小数点にし、ラベルをワンホットベクトルにしておきます。
モデル
モデルは畳み込み4層を定義したあとに平滑化し、全結合層を3層繋げます。全結合層の最後では、5クラス分類用に調整します。
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=in_shape))
model.add(BatchNormalization())
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(5, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adam(),
metrics=['accuracy'])
データ拡張
そのまま学習しても良いですが、今回はデータ拡張をしてみます。訓練データはデータ拡張(回転やフリップなど)を行い、検証データは何もしないジェネレータをそれぞれ作成しました。
train_gen = ImageDataGenerator(rotation_range=8,
width_shift_range=0.08,
shear_range=0.3,
height_shift_range=0.08,
zoom_range=0.08)
val_gen = ImageDataGenerator()
ImageDataGeneratorのflowを使うと、バッチサイズ分データを読み込んでくれます。今回は適当にバッチサイズ32を指定しました。一般的には、データセットが数百枚ならバッチサイズは32~64、数万枚なら256を指定するようです。
train_batches = train_gen.flow(X_train, y_train, batch_size=32)
val_batches = val_gen.flow(X_val, y_val, batch_size=32)
history = model.fit_generator(train_batches, steps_per_epoch=2240//32, epochs=50,
validation_data=val_batches, validation_steps=560//32, use_multiprocessing=True)
定義したモデルのfit_generatorを使います。これを使うとジェネレータを使用した学習をすることができます。Steps_per_epochは、”訓練データの枚数/バッチサイズ”を指定します。小数点以下は切り捨てて整数値にします。
Validation_stepsでは、同様に、”検証データの枚数/バッチサイズ”を指定します。
エポックは何回学習させるかですが、適当に50回を指定しました。
エポック数は通常損失コスト(ロス)が収束するまで指定するのが普通ですが、実際に学習を回してみないとどの程度で収束するのか分かりません。
適当に設定してトライしてみるようにしています。
学習結果を可視化した結果が以下の通りです。
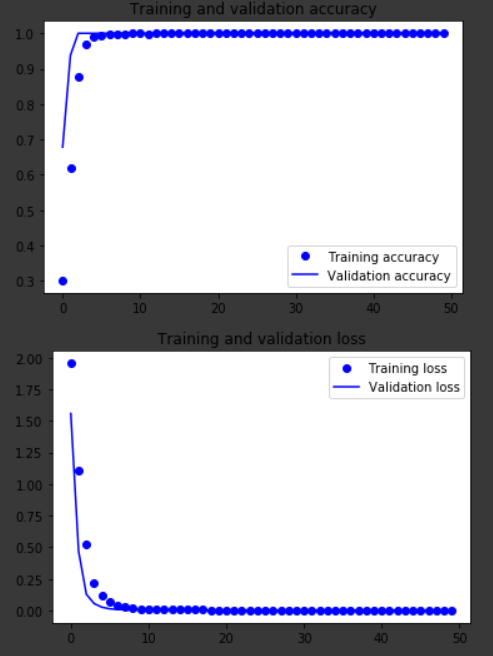
グラフの通り10エポックほどで検証精度が100%まで行きました。
テストでも同様に100%の精度でした。
感想
精度向上のためにモデル拡張やファインチューニングを試そうと思っていたのですが、あっさり100%が出たのでここで終わりにします。
5クラス分類なのでもう少し難しいかと思っていましたがそうでもありませんでした。
花くらい分かりやすい画像だと他クラス分類でも今のAIなら十分認識できるみたいです。
おわり。