こんにちは。のっくん(@yamagablog)です。
この記事では機械学習を使って手書き数字の認識にチャレンジしてみます。
[toc]
データセット
scikit-learnに付属している手書き数字データセットを使ってみます。
「Optical Recognition of Handwritten Digits Data」、手書き数字の光学認識データセットと言う長い名前のデータセットです。
8×8ピクセルの手書き数字データが5620個用意されています。
https://archive.ics.uci.edu/ml/datasets/optical+recognition+of+handwritten+digits

環境構築
ローカルのMacでやっても良いのですが、今回はUbuntuにsshでアクセスしてその上で環境構築をします。
UbuntuにAnacondaがインストール済みの前提で進めていきます。
digitsと言う名前の仮想環境を作ります。anacondaのパッケージをインストールするように指定しています。Pythonのバージョンは3.6にします。
#仮想環境の作成 $conda create -n digits python=3.6 anaconda #仮想環境の一覧 $conda info -e # conda environments: # base * /home/matsu/anaconda3 digits /home/matsu/anaconda3/envs/digits # アクティベート $source activate digits # opencvのインストール (digits)$pip install opencv-python # jupyterの起動 (digits)$jupyter notebook
これで、準備が出来ました。macからjupyterにアクセスしてコードを書いていきます。
学習
from sklearn.model_selection import train_test_split from sklearn import datasets,svm,metrics from sklearn.metrics import accuracy_score digits = datasets.load_digits() x = digits.images y = digits.target #二次元配列を一次元配列に変換 x = x.reshape((-1,64)) # データを学習用とテスト用に分割する x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2) # データを学習 clf = svm.LinearSVC() clf.fit(x_train, y_train) # 予測して精度を確認する y_pred = clf.predict(x_test) print(accuracy_score(y_test, y_pred))
実行してみると、、
0.9444444444444444
高精度で識別出来ました。
以下のコードを実行して、学習済みデータを保存しておきます。
from sklearn.externals import joblib joblib.dump(clf, 'digits.pkl')
自分で書いた文字をテストする
さて、ここで自分の書いた文字を試してみます。
ちなみに、画像の読み込みにはcv2を使うのですがインポートしてみるとエラーが出ました。
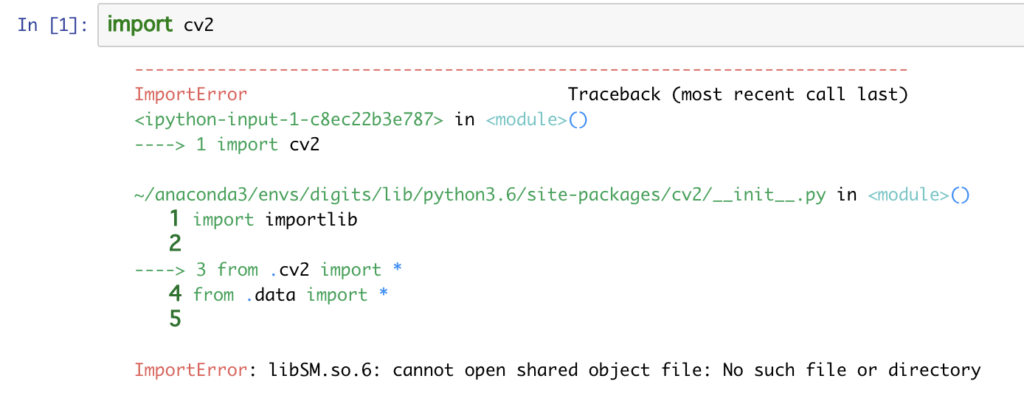
ん? なんだ?
「libSM.so.6が無いよ。ばかやろー」
と怒られています。以下のコマンドで必要なライブラリをubuntuに入れましょう。
sudo apt-get install libsm6 libxrender1 libfontconfig1
これで解決です。
では私の書いた美しい「3」を認識できるか試してみます。

「three.png」と言う名前で保存しました。
import cv2
from sklearn.externals import joblib
def predict_digit(filename):
clf = joblib.load("digits.pkl")
#画像を読み込む
my_img = cv2.imread(filename)
#グレースケールに変換する
my_img = cv2.cvtColor(my_img, cv2.COLOR_BGR2GRAY)
# 8 * 8のサイズに変換する
my_img = cv2.resize(my_img,(8,8))
#白黒反転する
my_img = 15 - my_img // 16
#二次元を一次元に変換
my_img = my_img.reshape((-1,64))
res = clf.predict(my_img)
return res[0]
n = predict_digit("three.png")
print("three.png = " + str(n))
さぁ、3来い!
three.png = 9
[speech_bubble type=”ln” subtype=”L1″ icon=”ilust/cat2_1_idea.png” name=”ネコ”]違ってるー!![/speech_bubble]
[speech_bubble type=”ln” subtype=”L1″ icon=”profile_face.png” name=”のっくん”]残念だったねw まぁ、3と9似てるからしょうがないよねw
[/speech_bubble]
リベンジで「2」を書いてテストしてみました。

two.png = 2
今度は合ってますね。めでたしめでたし。
参考
「PythonによるAI・機械学習・深層学習アプリ」のつくり方