
こんにちは、のっくんです。
今日はフルーツの画像をディープラーニングを使って分類してみました。
[toc]
画像の読み込み
使用するデータはいつものようにkaggleからダウンロードしました。
https://www.kaggle.com/moltean/fruits
まず画像の読み込みですが、ダウンロードしたデータ形式によってどうやって読み込むか違います。
今回の場合は、trainとtestでフォルダが別れていました。
フォルダがすでに別れている場合には、kerasのImageDataGeneratorの関数`flow_from_directory`を使うのが有効です。
114クラス、7万枚と巨大なデータセットになっているので、私の好きな食べ物(桃やサクランボなど)を13種類選んで分類するようにしました。
IMG_WIDTH = 40
IMG_HEIGHT = 40
CHANNELS = 3
TARGET = ["Apple Golden 1","Avocado","Banana","Blueberry","Cherry 1","Grape Pink","Kaki",
"Lemon","Mango","Onion Red","Peach","Strawberry","Tomato 1"]
train_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_path,
target_size=(IMG_WIDTH,IMG_HEIGHT),
batch_size=20,
classes=TARGET,
class_mode="categorical"
)
このように対象ラベルをリストにする事で、全てのデータを読み込むのではなく好きなクラスを選んで読み込むことができます。
画像のサイズは40pxにしましたが、すいません、割と適当です。
ジェネレータの引数にはあえて、データ拡張のパラメータは指定していません。
反転したり回転させて水増しするのが恒例ですが、今回はまず普通に読み込んでみます。
訓練画像から一枚ずつ表示してみると以下のようになります。

13種類を表示してみるとこんな感じ。柿は”Kaki”なんですね。
背景が単一で果物が1つしか写っていないので、割と分類しやすいです。
テスト画像の方も同様にジェネレータで読み込むようにしました。
validation_datagen = ImageDataGenerator(rescale=1./255)
validation_generator = validation_datagen.flow_from_directory(
test_path,
target_size=(IMG_WIDTH,IMG_HEIGHT),
batch_size=20,
classes=TARGET,
class_mode="categorical"
)
ネットワークモデル
畳み込みニューラルネットは以下の通り。
model = models.Sequential() model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(IMG_WIDTH,IMG_HEIGHT,CHANNELS))) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Conv2D(64,(3,3),activation="relu")) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Conv2D(128,(3,3),activation="relu")) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Conv2D(128,(3,3),activation="relu")) model.add(layers.MaxPooling2D((2,2),padding="SAME")) model.add(layers.Flatten()) model.add(layers.Dense(512,activation="relu")) model.add(layers.Dense(len(trained_classes_labels),activation="sigmoid")) model.summary()
ちなみに4層目の畳み込み層の後に、”padding=SAME”と入れてありますがこれが無いとエラーが出ました。
エラー内容は以下の通りです。
ValueError: Negative dimension size caused by subtracting 2 from 1 for ‘max_pooling2d_4/MaxPool’ (op: ‘MaxPool’) with input shapes: [?,1,1,128].
第4層のプーリングの段階で、次元サイズが[?,1,1,28]になってて、これ以上プーリングできませんと言っています。
ニューラルネットを作る時には、以下の点に注意します。
- 畳み込みを行うことで、Output Shape(出力形状)は半分になる。
- 2×2のプーリングを行うことで、Output Shape(出力形状)は-2になる。
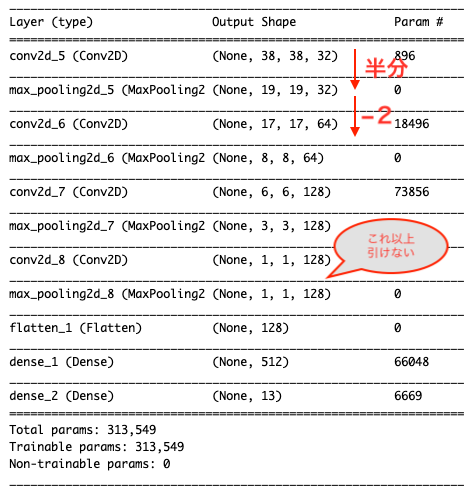
入力画像サイズが小さい時などにプーリングができなくなった時には上記のエラーが出ますが、paddingを設定することでエラーを回避できます。
学習
モデルをコンパイルし、学習します。
今回は通常の学習で使われるfitではなく、fit_generatorを使います。
fit_generatorでは、画像データ(X)やラベル(y)の代わりにジェネレータを指定し学習します。
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer = keras.optimizers.RMSprop(lr=1e-4, decay = 1e-6),
metrics=['accuracy'])
STEP_SIZE_TRAIN=train_generator.n//train_generator.batch_size
STEP_SIZE_VALID=validation_generator.n//validation_generator.batch_size
history = model.fit_generator(train_generator,
steps_per_epoch=STEP_SIZE_TRAIN,
epochs=10,
validation_data=validation_generator,
validation_steps=STEP_SIZE_VALID)
steps_per_epochには、訓練画像の枚数/バッチ数、validation_stepsには、検証画像/バッチ数を指定します。
学習結果
グラフで学習結果を表示する際に、以下のテーマを使用すると良い感じに表示できることがわかりました。
plt.style.use('fivethirtyeight')
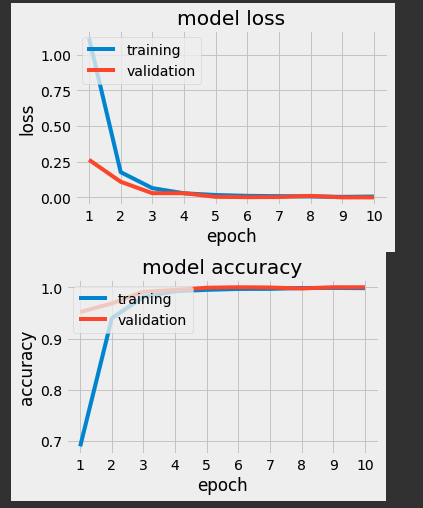
見やすくてかっこよくないですか?このグラフ。いいっすね〜〜。
精度は検証データで100%達成できました。
おわり。










