こんにちは、のっくんです。
今日はOCT画像をディープラーニングで学習して目の病気を判別するコードを書いていきたいと思います。
データセットは以下に公開されているものを使ってみたいと思います。
(目ん玉がたくさんあってグロいのでアクセスする際には注意)
https://www.kaggle.com/paultimothymooney/kermany2018
Retinal OCT Images、って書いてあるんですが、最初見たときなんのことがわかりませんでした。
retinaってMacのレティーナ・ディスプレイのイメージしかないよ。
retina = 網膜、らしい。
Retinal optical coherence tomography (OCT) ?なんじゃそりゃ。
OCT検査は、赤外線を利用して、網膜の断面を画像化することによって三次元的にとらえることができる
らしいです。
これが画像の例。
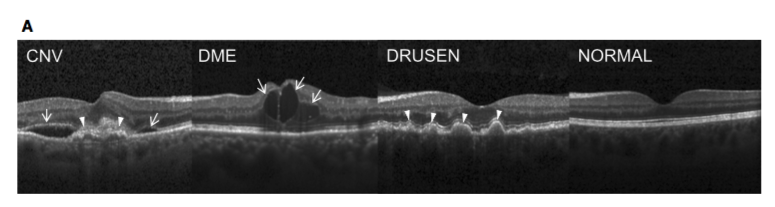
1番右が正常、他の3つは何かの病気。
うーん、わかりづらい。
野菜やフルーツの分類などと違って、人が見てもわかりづらいので難易度は高めかと思います。
毎年3000万のOCT画像が撮影され、それらを分析するのはとても時間がかかるそうです。
まぁ、そういうのはAIにやってもらいましょう。
このデータセットですが、何と5GBあります。
私が過去にチャレンジしたKaggleのデータセットの中で最大級の大きさ。
そして枚数が8万4千枚とかなり多い。
中身を解凍するとtrain,val,testにディレクトリが分かれているのですが、valには1カテゴリあたり8枚しか入っていない。
データが偏りすぎだろ。。。
ほとんどの画像はtrainの中に入っています。
ということでtrainの中から、データを読み込み、訓練用と検証用に分けていく方向で進めます。
ちなみに、私のPCのスペックは以下の通り。
- メモリ16GB
- ubuntu 18.04
- GPU Geforce GTX 1060
データの読み込み
そんなにメモリがあるわけではないので、ジェネレータを使ってメモリを節約していくスタイルでいくよ。
train_datagen = ImageDataGenerator(samplewise_center=True,
samplewise_std_normalization=True,
horizontal_flip = True,
vertical_flip = False,
height_shift_range= 0.05,
width_shift_range=0.1,
rotation_range=15,
zoom_range=0.15,
validation_split=0.2)
データ拡張するために、画像にランダムで水平フリップ、ズーム、回転を加えます。
ポイントは最後の`validatoin_split`。実はジェネレータでも分割でき、2割を検証用、8割を訓練用に使います。
次に、flow_from_directoryを使って、ディレクトリから画像をバッチサイズ分読むこむためのジェネレータを作成します。引数には、バッチサイズの他に、
- 訓練画像のパス
- 画像サイズ(target_size)
- バッチサイズ
- サブセット(訓練用の場合はtraining, 検証用の場合はvalidation)
- クラスモード、クラス分類の場合はcategoricalを指定します。2値分類の場合はbinary?かな。
IMG_SIZE = 224
train_data_dir = 'OCT2017/train'
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(IMG_SIZE , IMG_SIZE),
batch_size=16,
subset='training',
class_mode='categorical')
valid_X, valid_Y = next(train_datagen.flow_from_directory(
train_data_dir,
target_size=(IMG_SIZE , IMG_SIZE),
batch_size=4000,
subset='validation',
class_mode='categorical'))
訓練用画像のためにジェネレータオブジェクトを生成します。
検証用画像は`next`を使ってジェネレータオブジェクトを回し、4000枚生成して変数に代入しておきます。
検証用の方もジェネレータオブジェクトで`fit_generator`に渡すのが普通ですが、学習実行時にメモリ不足のエラーが発生したので、検証用の方だけでも予めメモリに展開して保持するようにします。
上記のコードの実行結果です。
Found 66788 images belonging to 4 classes. Found 16696 images belonging to 4 classes.
訓練用に66788枚、検証用に16696枚、分割されました。
ResNet50
モデルにはResNet50を使って転移学習します。
下記のサイトに掲載されていたニューラルネットの各精度を見てみると、ResNetやInceptionの精度が高いことがわかります。
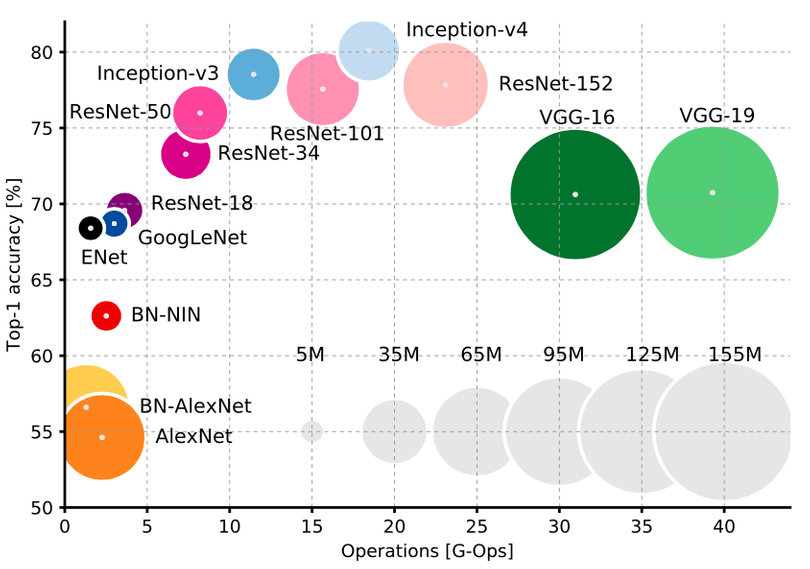
https://www.liip.ch/en/blog/zoo-pokedex-part-2-hands-on-with-keras-and-resnet50
Resnetは精度が高い割には、VGGほどネットワークのサイズが大きくなりません。
resはresidual(残差)から名付けられたもので入力された特徴量を途中で間引きます。
間引いた特徴量をより深い層に短絡(short-circuiting)させることで、精度を高めるようです。
imagenetで学習した重みを使います。
Resnet50の全結合層は含めずに、今回の4分類のために新しく定義した全結合層を加えます。
def resnet_model():
img_in = Input(t_x.shape[1:])
model = ResNet50(include_top= False ,
weights='imagenet',
input_tensor= img_in,
input_shape= t_x.shape[1:],
pooling ='avg')
x = model.output
predictions = Dense(4, activation="softmax", name="predictions")(x)
model = Model(inputs=img_in, outputs=predictions)
return model
学習時には、`fit_generator`を使います。
各パラメータは以下の通り。
- train_generator, 訓練用のジェネレータオブジェクト
- steps_per_epoch, 1エポック実行するときの画像枚数。通常であれば、訓練画像の合計枚数/バッチサイズを指定しますが、今回は訓練画像があまりにも多く、ステップ数が多くなりがち(66000/16≒4000)ので100に固定しました。なにせ1エポックに20分とかかかりそうだったので。
- validation_data, 先ほどメモリ展開した4000枚分の検証用データとラベルです。
- epochs, 何回学習を実行するかです。適当に30を指定。
- callbacks, これは無くても良いです。モデルを保存したい場合やEarlyStoppingを指定するときに使用。
# training model
history = model.fit_generator(train_generator,
steps_per_epoch=100,
validation_data = (valid_X,valid_Y),
epochs = 30,
callbacks=callbacks_list)
実行結果は以下の通り。
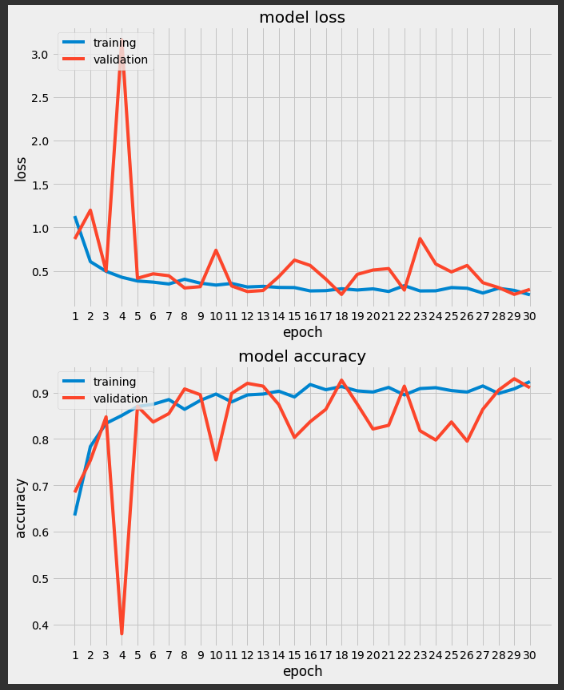
バリデーションの最高精度は93.0%でした。
悪くないですね。
InceptionV3
せっかくなので、InceptionV3を使って同じ条件で学習させてみました。
def inception_v3():
img_in = Input(shape = (IMG_SIZE,IMG_SIZE,3))
model = InceptionV3(include_top= False ,
weights='imagenet',
input_tensor= img_in,
input_shape= (IMG_SIZE,IMG_SIZE,3),
pooling ='avg')
x = model.output
predictions = Dense(4, activation="softmax", name="predictions")(x)
model = Model(inputs=img_in, outputs=predictions)
return model

バリデーションでの精度は、93.90%
さらに良くなりました。
感想
最初データセットを見たときに8万枚?絶対メモリ足りなくなると思いましたが、ジェネレータを駆使することで家のPCでも学習させることができました。
kerasを使うと優秀な研究者が作ったモデルや重みをそのまま転用できるのでとても便利です。
実は、DenseNet121も一度使って見たのですが、こちらはメモリエラー(ResourceExhaustedError)で学習できませんでした。残念。
おわり。