こんにちは、のっくんです。
今日は機械学習を使ってタイタニックの生存者を予測するコードを書いてみたいと思います。
[toc]
データの場所
データセットは以下のサイトからダウンロードします。
https://www.kaggle.com/c/titanic/data
このデータセットの中には下記のものが含まれていました。
- train.csv
- test.csv
- gender_submission.csv
まずは中身をみてみることに。
import pandas as pd
train_df = pd.read_csv("train.csv")
test_df = pd.read_csv("test.csv")
print(train_df.shape)
print(test_df.shape)
#(891, 12)
#(418, 11)
えー、テストの方なんで1カラム少ないの?
と思いながら中身を見てみると、test.csvにはラベル(Survived)が含まれていませんでした。
ラベルがないと答え合わせできないじゃん。
「gender_submission.csvがkaggleに提出するべきデータフォーマットの例だよ。」
みたいなことが書かれているので、もしかしたらtest.csvの正解はkaggleに提出しないと分からないのかもしれません。
(kaggleに予測したデータを提出する気はありません)
ってことで、私にはtest.csvはいらない子でした。
まぁtrain.csvのデータを訓練とテスト用に自分で分割するコードを書けば問題なしです。
train.csvのみを使って訓練とテストをやっていきたいと思います。
データの分析
最初の5行表示してみるよー。
train_df.head(5)

余談ですが、jupyter notebookの背景色を変えて見たんですが、かっこよくないですか?
背景色は黒に限りますよ。
カラムの意味は以下の通り。
- PassangerID、客のIDですね。まぁ今回はいらない子。
- Survived, 0=死亡、1=生き残り
- Pclass, 1=上流家庭、2=中流家庭、3=下流家庭、みたいな感じ。
- Name, 名前、これもいらない子。
- Sex, 性別
- Age,年齢
- SibSp, 一緒に乗船している兄弟、姉妹、妻、夫の数
- Parch, 一緒に乗船している親、子供の数
- Ticket, チケットの名称?いらない子。
- Fare, 支払い運賃
- Cabin, キャビン?、ほとんどNaNなのでいらない子。
- Embarked, 乗船する都市、3種類ある。C = Cherbourg, Q = Queenstown, S = Southampton。
次にデータの概要を見てみるよ。
train_df.describe()
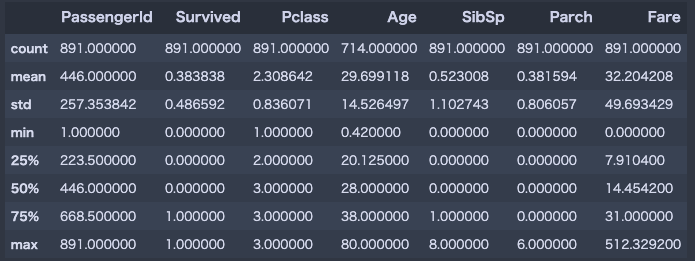
以下のことが分かります。
- Survivedの平均が0.3なので、死んだ人の方が多い。
- Pclassの平均が2.3なので、中流〜下流の人が多い。
- 年齢の平均は29才。
- 乗船していた親や兄弟の数は平均して1人くらい。
- 運賃は、平均して32ドル。最低は0ドル、最高は512ドル。
運賃って固定額じゃないんですね。自分の好きな額払う感じなのでしょうか。この辺はイマイチよく分かりませんでした。
続けてデータを分析してみます。
年齢ごとに生き残った人の割合を見てみましょう。
# 女性の方が生き残っている割合が多い
train_df.groupby("Sex")[["Survived"]].mean()
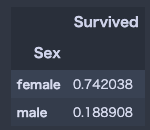
圧倒的に男性が死んでいます。なんでだろう。
次に階級ごとの死亡率をグラフで見てみます。
import seaborn as sns sns.barplot(x="Pclass",y="Survived",data=train_df)

生き残ったのは上流階級の人が多いですね。
上流:中流:下流=6割:5割:2割
の生存率でしょうか。
何ででしょうかね。多分ですが、以下の理由が考えられるかと思います。
- 上流の人はより安全な部屋にいた
- 上流の人は生き残りたいと思う気持ちが強かった
- 上流の人は日頃から筋トレをしていて生き延びやすかった
邪推してみると面白いです。
次に年齢、性別、階級の関係をみてみましょう。
age = pd.cut(train_df['Age'],[0,18,80])
train_df.pivot_table("Survived",["Sex",age],"Pclass")
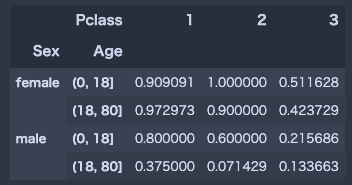
0-18才の子供の方がより多く生き残っていたことが分かります。
特に男性で顕著ですね。
子供の方が体が小さく身動きが取りやすい分、狭い場所を通りぬけできたので生き延びやすかったのでしょうか。
子供や女性を助けようとして自ら犠牲になった18歳以上の成人男性が多かったのかもしれません。
そう考えると泣けてきますね。
すいません、映画のタイタニックは見ていないので真実は分かりません。
次に階級ごとの支払い金額を見てみます。
import matplotlib.pyplot as plt
plt.scatter(train_df['Fare'], train_df['Pclass'], color = 'blue', label='Passenger Paid')
plt.ylabel('Class')
plt.xlabel('Price / Fare')
plt.title('Price Of Each Class')
plt.legend()
plt.show()

上流階級の人たちは運賃を多めに払っている人が多いみたいです。
上流階級の人が生き残っている割合が多いことは、多めに運賃を払ってより安全な部屋に宿泊していたからかもしれませんね。
これが正しいとすれば、支払い運賃が高めの人は生き残りやすいという分析ができるかと思います。
中級〜下流はあんまり変わらないです。
以上のことから以下のことが分かります。
「タイタニックで生き残っているかどうかを判別するには、年齢、階級、性別、運賃が重要な要素になりそう」
データの整形
いらない列や行を削除していきます。
性別や都市名の文字列データは数値に変換します。
# Cabin列を落とす train_df = train_df.drop(["Cabin"],axis=1) # Age、EmbarkedにNaが含まれる行を落とす train_df = train_df.dropna(subset=["Age","Embarked"]) # Name,Ticket列を落とす train_df = train_df.drop(["Name","Ticket"],axis=1) # 年齢と乗船した都市名を数値に変換する from sklearn.preprocessing import LabelEncoder labelencoder = LabelEncoder() train_df.iloc[:,3]= labelencoder.fit_transform(train_df.iloc[:,3].values) train_df.iloc[:,8]= labelencoder.fit_transform(train_df.iloc[:,8].values) print(train_df['Sex'].unique()) print(train_df['Embarked'].unique()) #[1 0] #[2 0 1]
整形後のデータは以下の通り。
train_df.dtypes #PassengerId int64 #Survived int64 #Pclass int64 #Sex int64 #Age float64 #SibSp int64 #Parch int64 #Fare float64 #Embarked int64 #dtype: object train_df.shape #(712, 9)
712行、9列のデータが出来上がりました。
これをもとに機械学習を仕上げていきたいと思います。
機械学習
ここからはいつものように決まった形式で機械学習をかけていきます。
以下の7つの機械学習を使ってみます。
- 線形回帰
- K近傍法
- SVM(線形分類器)
- SVM(RBF分類器)
- ナイーブベイズ
- 決定木
- ランダムフォレスト
まずは訓練データを使って、学習、精度判定してみます。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
# numpyの配列として値を取り出す
X = train_df.iloc[:, 2:9].values
Y = train_df.iloc[:,1].values
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0)
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
def models(X_train,Y_train):
log = LogisticRegression(random_state = 0)
log.fit(X_train, Y_train)
knn = KNeighborsClassifier(n_neighbors = 5, metric = 'minkowski', p = 2)
knn.fit(X_train, Y_train)
svc_lin = SVC(kernel = 'linear', random_state = 0)
svc_lin.fit(X_train, Y_train)
svc_rbf = SVC(kernel = 'rbf', random_state = 0)
svc_rbf.fit(X_train, Y_train)
gauss = GaussianNB()
gauss.fit(X_train, Y_train)
tree = DecisionTreeClassifier(criterion = 'entropy', random_state = 0)
tree.fit(X_train, Y_train)
forest = RandomForestClassifier(n_estimators = 10, criterion = 'entropy', random_state = 0)
forest.fit(X_train, Y_train)
print('[0]Logistic Regression Training Accuracy:', log.score(X_train, Y_train))
print('[1]K Nearest Neighbor Training Accuracy:', knn.score(X_train, Y_train))
print('[2]Support Vector Machine (Linear Classifier) Training Accuracy:', svc_lin.score(X_train, Y_train))
print('[3]Support Vector Machine (RBF Classifier) Training Accuracy:', svc_rbf.score(X_train, Y_train))
print('[4]Gaussian Naive Bayes Training Accuracy:', gauss.score(X_train, Y_train))
print('[5]Decision Tree Classifier Training Accuracy:', tree.score(X_train, Y_train))
print('[6]Random Forest Classifier Training Accuracy:', forest.score(X_train, Y_train))
return log, knn, svc_lin, svc_rbf, gauss, tree, forest
model = models(X_train,Y_train)
#[0]Logistic Regression Training Accuracy: 0.7978910369068541
#[1]K Nearest Neighbor Training Accuracy: 0.8664323374340949
#[2]Support Vector Machine (Linear Classifier) Training Accuracy: 0.7768014059753954
#[3]Support Vector Machine (RBF Classifier) Training Accuracy: 0.8506151142355008
#[4]Gaussian Naive Bayes Training Accuracy: 0.8031634446397188
#[5]Decision Tree Classifier Training Accuracy: 0.9929701230228472
#[6]Random Forest Classifier Training Accuracy: 0.9753954305799648
結果としては
決定木(99.2%)>ランダムフォレスト(97.5%)>K近傍法(86.6%)
の順番で高い精度が出ました。
テストデータでの評価
次に作成したモデルを使ってテストデータで評価してみます。
精度評価には、混同行列(Confusion Matrix)を使います。
Confusion Matrixを使うと、以下の4つの要素が分かります。
- True Positive(TP)、正しく陽性と判断した
- True Negative(TN)、正しく陰性と判断した
- False Positive(FP)、間違って陽性と判断した
- False Negative(FN), 間違って陰性と判断した
正解率は以下の式で求められます。
正解率=(TP + TN) / (TP + TN + FP + FN)
from sklearn.metrics import confusion_matrix
for i in range(len(model)):
cm = confusion_matrix(Y_test, model[i].predict(X_test))
#extracting TN, FP, FN, TP
TN, FP, FN, TP = confusion_matrix(Y_test, model[i].predict(X_test)).ravel()
print(cm)
print('Model[{}] Testing Accuracy = "{} !"'.format(i, (TP + TN) / (TP + TN + FN + FP)))
print()# Print a new line
#[[73 9]
# [18 43]]
#Model[0] Testing Accuracy = "0.8111888111888111 !"
#[[71 11]
# [20 41]]
#Model[1] Testing Accuracy = "0.7832167832167832 !"
#[[70 12]
# [18 43]]
#Model[2] Testing Accuracy = "0.7902097902097902 !"
#[[75 7]
# [22 39]]
#Model[3] Testing Accuracy = "0.7972027972027972 !"
#[[69 13]
# [23 38]]
#Model[4] Testing Accuracy = "0.7482517482517482 !"
#[[60 22]
# [10 51]]
#Model[5] Testing Accuracy = "0.7762237762237763 !"
#[[67 15]
# [13 48]]
#Model[6] Testing Accuracy = "0.8041958041958042 !"
訓練画像と同じ結果が出ると思いきや別の結果が出ました。
この辺りが機械学習の難しいところですね。
線形回帰(81.1%) > ランダムフォレスト(80.4%) > SVM(RBF分類器)(79.7%)
訓練データ、テストデータの評価結果を踏まえると、共にベスト2にランクインしたランダムフォレストが1番良い精度と考えて良いでしょう。
ランダムフォレストが重要だと判断したデータを判定してみます。
学習済みのモデルには、feature_importances_という変数が用意されており、これを参照するとどのデータを重要だと判断したかが分かります。
import numpy as np
forest = model[6]
importances = pd.DataFrame({'feature':train_df.iloc[:, 2:9].columns,'importance':np.round(forest.feature_importances_,3)})
importances = importances.sort_values('importance',ascending=False).set_index('feature')
importances.plot.bar()
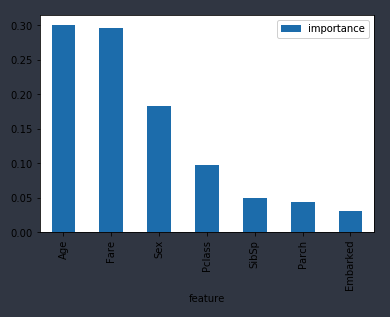
機械学習によって重要と判断された特徴は順番に、
年齢>運賃>性別>階級
でした。
個人的な感想としては、
- 階級ってもっと重要なものだと思ってた
- 運賃ってそんなに重要な要素なの!?
って感じでした。
うーん、奥が深いですね。機械学習。
おまけ
ここまで読んでくれてありがとうございます。
最後に、もし自分がタイタニック号に乗っていたらどうなっていたかを予測してみたいと思います。
私の場合だったら以下のようなデータになると思います。
- 階級:いやー、下流ですよ。豪華客船に乗るような人に比べたら。しがない社畜サラリーマンなので。
- 性別:男性です。
- 年齢:30才です。
- 兄弟や夫妻:行くとしたら妻と行くので一人と記載しましょうか。
- 親や子供:親や子供とは行きません。子供はいません!
- 運賃:まぁ流石に豪華客船だから100(ドル?)くらいは払っても良いでしょう。
- 乗船町:サウサンプトンかな。吉田麻也のいるサウサンプトン。
my_survival = [[3,1,30,1, 0, 100, 2]]
#Print Prediction of Random Forest Classifier model
pred = model[6].predict(my_survival)
print(pred)
if pred == 0:
print('死亡しました')
else:
print('生き残ったよ!')
#[1]
#生き残ったよ!
男性、18歳以上、下流階級、と高確率で死ぬと思いましたが生き残ると判断されました。
おそらく誰も助けずに一人で逃げて生き延びるタイプでしょう。
おわり。