Pandasのデータフレームから特定の行を削除したい。
そんな時のために削除する方法をまとめておきます。
行そのものを削除するには行番号を指定すれば良いですが、1つだけでなく複数の行を一度に消すこともできます。
それぞれの方法をみていきましょう。
[toc]使用するデータ
以下のサンプルデータを使います。
# List of Tuples
students = [ ('jack', 34, 'Sydeny' , 'Australia') ,
('Riti', 30, 'Delhi' , 'India' ) ,
('Vikas', 31, 'Mumbai' , 'India' ) ,
('Neelu', 32, 'Bangalore' , 'India' ) ,
('John', 16, 'New York' , 'US') ,
('Mike', 17, 'las vegas' , 'US') ]
#Create a DataFrame object
df = pd.DataFrame(students, columns = ['Name' , 'Age', 'City' , 'Country'])
jupyter notebook上で表示されるデータフレームは以下の通りです。
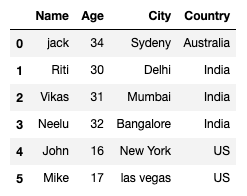
名前や年齢などの4つの列(カラム)と6つの行で構成されます。
行番号を示す左の数字がインデックスと呼ばれるものです。
インデックス番号を指定して削除
このインデックスを指定して行を削除していきます。
# 1番目を消します。インデックスを再度0から振り直しています。 df.drop(df.index[1], inplace=True) df.reset_index(inplace=True,drop=True) df
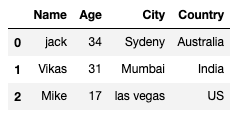
1番目の行を削除するコードです。
inplaceをTrueにしていますが、これはデータフレームに削除した結果を反映させるためです。
その下では、reset_indexを行っています。
これはその名の通り、インデックスを再度振り直すものです。
指定しなかった場合、[0,2,3,4,5,6]のように1番が歯抜けの見辛いデータになります。
一度だけなら良いですが、複数回データを操作する時にはインデックスは振り直すことをオススメします。
drop=Trueにすることで、インデックスを振り直す前の歯抜けのインデックスを列として保持せずに破棄します。
実行結果は以下の通り。
複数のインデックス番号をリストに入れて、複数の行を削除する
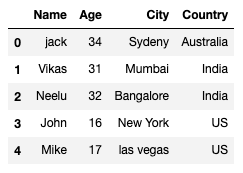
先ほどの例では1つの行だけ削除しましたが、複数の行を一度に削除することもできます。
例えば、削除するインデックスのリストを与えて一度に複数行を削除してみましょう。
#2番目と3番目を消します。リストで渡すこともできます。 delete_list = [2,3] df.drop(df.index[delete_list], inplace=True) df.reset_index(inplace=True,drop=True) df
実行結果は以下の通り。