こんにちは、のっくんです。
カメラに映った画像を機械学習を使って識別するiPhoneアプリを作ってみました。
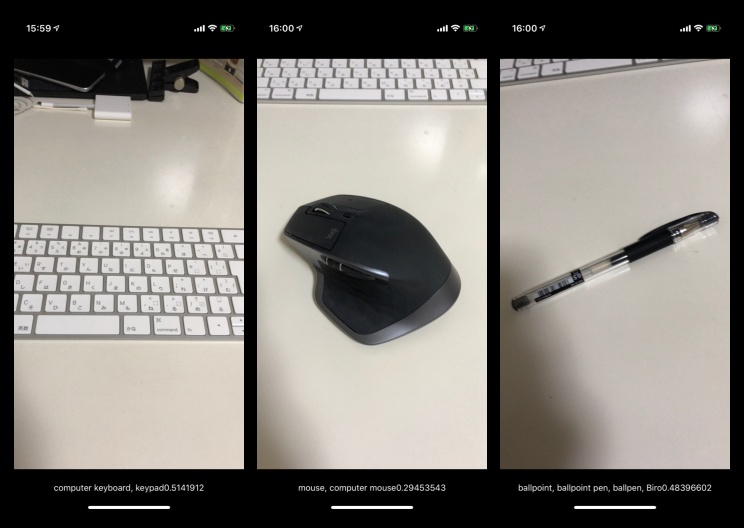
アプリの機能としては以下の通り。
- カメラからプレビュー画像を取得する
- プレビュー画像に映っている物体をCoreMLモデルを使って推定する
やってみた感想としては、アプリはサクサク動くし、物体認識も正確なので流石はAppleだなぁという感じ。
シンプルで短いコードで実装できるので、デベロッパーに優しいと思います。
では早速みていきたいと思います。
カメラ画像をViewに表示する
アプリのViewにカメラ画像を表示します。
AVKitを使ってカメラ画像を取得してViewに表示しましょう。
import AVKit
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view.
// デバイスにビデオを指定する
let captureDevice = AVCaptureDevice.default(for: .video)
let input = try? AVCaptureDeviceInput(device: captureDevice!)
let capureSession = AVCaptureSession()
// セッションを開始する
capureSession.addInput(input!)
capureSession.startRunning()
//ビデオのプレビューをビューに表示するようにする
let previewLayer = AVCaptureVideoPreviewLayer(session: capureSession)
view.layer.addSublayer(previewLayer)
previewLayer.frame = view.frame
}
カメラは実機でないと動かせませんが、info.plistで以下の許可を得るようにしないとエラーが発生しますのでご注意を。

フレームを1枚ずつ処理する
カメラに映ったフレーム画像を1枚1枚処理するにはどうすれば良いのでしょうか。
AVCaptureVideoDataOutputSampleBufferDelegateという名のとても長いプロトコルに批准することで各画像の処理ができるようになります。
class ViewController: UIViewController, AVCaptureVideoDataOutputSampleBufferDelegate
この辺りの機能を用意してくれているのも流石はAppleですね。
以下のコードをviewDidLoadに追加します。
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view.
// デバイスにビデオを指定する
let captureDevice = AVCaptureDevice.default(for: .video)
let input = try? AVCaptureDeviceInput(device: captureDevice!)
let capureSession = AVCaptureSession()
// セッションを開始する
capureSession.addInput(input!)
capureSession.startRunning()
//ビデオのプレビューをビューに表示するようにする
let previewLayer = AVCaptureVideoPreviewLayer(session: capureSession)
view.layer.addSublayer(previewLayer)
previewLayer.frame = view.frame
let dataOutput = AVCaptureVideoDataOutput()
dataOutput.setSampleBufferDelegate(self, queue: DispatchQueue(label: "videoQueue"))
capureSession.addOutput(dataOutput)
}
デリゲートを設定してフレームの処理を委任します。別のキューで処理するようにキューと名前を指定しています。
プロトコルに批准するとメソッドcaptureOutputを実装できるようになります。
sampleBufferがフレーム画像のことです。
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
print("Camera frame",Date())
}
上記のコードを実行するとフレームが取れるごとに時間が出力されるようになります。
機械学習
機械学習の処理を追加していきましょう。
機械学習にはCoreMLModelを使います。
CoreMLモデルはAppleが開発者のために提供しており、以下のサイトに置いてありますのでありがたく使わせてもらいます。
https://developer.apple.com/jp/machine-learning/models/
今回はResnet50を試してみます。
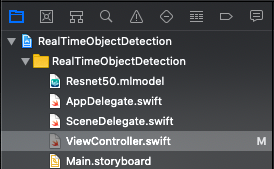
こんな感じでモデルをプロジェクトに追加します。
// AVCaptureVideoData....プロトコルに批准すると使えるようになる。フレームを処理するための関数。
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
// print("Camera frame",Date())
let pixelBuffer:CVPixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer)!
let model = try? VNCoreMLModel(for: Resnet50().model)
// VNCoreMLRequestを呼ぶとモデルが推測した結果が返ってくる
let request = VNCoreMLRequest(model: model!, completionHandler: {
(finishReq, err) in
// print(finishReq.results)
let results = finishReq.results as? [VNClassificationObservation]
//確率の高い最初の予測だけ取り出す。
let firstObservation = results?.first
// 識別結果と確率を表示する
DispatchQueue.main.async {
self.observeLabel.text = firstObservation!.identifier + String(firstObservation!.confidence)
}
})
// ピクセルバッファと上記のリクエストを指定して実行する。
try? VNImageRequestHandler(cvPixelBuffer: pixelBuffer, options: [:]).perform([request])
}
大まかな処理の流れとしては、以下の通り。
- フレーム画像を`CVPixelBuffer`に変換する
- モデルを読み込む
- `VNCoreMLRequest`を呼ぶと、物体認識の結果が返ってくるので表示する
シンプルなコードでサクッと機械学習が使えてしまうところがSwiftの素晴らしいところですね。
今後のAppleのアップデートにも期待です。