
こんにちは。のっくんです。
今日はOpenCVのDNN(Deep Neural Network)を使って、物体検出をしてみようと思います。
なんか難しそうに聞こえますが、コードのコピペで動きますし、やっていることは単純です。
ニューラルネットワークというと、GPUが必要なんじゃない?って思う方もいるかも知れませんが、訓練済みモデルを使えば、CPUやラズパイでも動作させることが可能です。
この記事では、ラズパイ上で物体検出できるかどうか試してみます。
[toc]
Object-Detection-APIとは?
物体の検出には、TensorFlowのObject-Detection-APIを使います。
https://github.com/opencv/opencv/wiki/TensorFlow-Object-Detection-API
今回はTensorFlowを含んでいるOpenCVを使って動かします。Object Detection APIを使うには、OpenCVは3.4.1より新しいものが必要みたい。(最新のOpenCV 4.0.0でも動きました。)
上のリンクを見てもらえば分かりますが、訓練済みモデルは色々あります。
- Mobile Net SSD v1
- Mobile Net SSD v2
- Inception SSD v2
- Faster-RCNN Inception v2
- Faster-RCNN ResNet-50
- Mask-RCNN Inception v2
どれを動かしても面白そうですが、今回はMobileNet SSD v2を動かしてみます。
環境は以下の通り。
- Python 3.5
- OpenCV 3.4.4
- MobileNet SSD v2
詳しくは以下のサイトを参考にしました。
https://heartbeat.fritz.ai/real-time-object-detection-on-raspberry-pi-using-opencv-dnn-98827255fa60
ソースコード、訓練済みモデル、設定ファイルは以下のサイトにあり、そのままクローンすれば動作確認できますよ!
https://github.com/rdeepc/ExploreOpencvDnn
コード
読みづらいコードだったので、私なりにリファクタリングしています。日本語のコメントも多めに記載してあります。
# coding: UTF-8
import cv2
import numpy as np
# モデルの中の訓練されたクラス
classNames = {0: 'background',
1: 'person', 2: 'bicycle', 3: 'car', 4: 'motorcycle', 5: 'airplane', 6: 'bus',
7: 'train', 8: 'truck', 9: 'boat', 10: 'traffic light', 11: 'fire hydrant',
13: 'stop sign', 14: 'parking meter', 15: 'bench', 16: 'bird', 17: 'cat',
18: 'dog', 19: 'horse', 20: 'sheep', 21: 'cow', 22: 'elephant', 23: 'bear',
24: 'zebra', 25: 'giraffe', 27: 'backpack', 28: 'umbrella', 31: 'handbag',
32: 'tie', 33: 'suitcase', 34: 'frisbee', 35: 'skis', 36: 'snowboard',
37: 'sports ball', 38: 'kite', 39: 'baseball bat', 40: 'baseball glove',
41: 'skateboard', 42: 'surfboard', 43: 'tennis racket', 44: 'bottle',
46: 'wine glass', 47: 'cup', 48: 'fork', 49: 'knife', 50: 'spoon',
51: 'bowl', 52: 'banana', 53: 'apple', 54: 'sandwich', 55: 'orange',
56: 'broccoli', 57: 'carrot', 58: 'hot dog', 59: 'pizza', 60: 'donut',
61: 'cake', 62: 'chair', 63: 'couch', 64: 'potted plant', 65: 'bed',
67: 'dining table', 70: 'toilet', 72: 'tv', 73: 'laptop', 74: 'mouse',
75: 'remote', 76: 'keyboard', 77: 'cell phone', 78: 'microwave', 79: 'oven',
80: 'toaster', 81: 'sink', 82: 'refrigerator', 84: 'book', 85: 'clock',
86: 'vase', 87: 'scissors', 88: 'teddy bear', 89: 'hair drier', 90: 'toothbrush'}
# モデルの読み込み
model = cv2.dnn.readNetFromTensorflow('models/frozen_inference_graph.pb',
'models/ssd_mobilenet_v2_coco_2018_03_29.pbtxt')
# テスト画像の読み込み
image = cv2.imread("img/laptop.jpg")
# 画像の縦と横サイズを取得
image_height, image_width = image.shape[:2]
# Imageからblobに変換する
model.setInput(cv2.dnn.blobFromImage(image, size=(300, 300), swapRB=True))
# 画像から物体検出を行う
output = model.forward()
# outputは[1:1:100:7]のリストになっているため、後半の2つを取り出す
detections = output[0, 0, :, :]
# detectionには[?,id番号、予測確率、Xの開始点、Yの開始点、Xの終了点、Yの終了点]が入っている。
for detection in detections:
# 予測確率を取り出し0.5以上か判定する。0.5以上であれば物体が正しく検出されたと判定する。
confidence = detection[2]
if confidence > .5:
# id番号を取り出し、辞書からクラス名を取り出す。
idx = detection[1]
class_name = classNames[idx]
# 検出された物体の名前を表示
print(" "+str(idx) + " " + str(confidence) + " " + class_name)
# 予測値に元の画像サイズを掛けて、四角で囲むための4点の座標情報を得る
axis = detection[3:7] * (image_width, image_height, image_width, image_height)
# floatからintに変換して、変数に取り出す。画像に四角や文字列を書き込むには、座標情報はintで渡す必要がある。
(start_X, start_Y, end_X, end_Y) = axis.astype(np.int)[:4]
# (画像、開始座標、終了座標、色、線の太さ)を指定
cv2.rectangle(image, (start_X, start_Y), (end_X, end_Y), (23, 230, 210), thickness=2)
# (画像、文字列、開始座標、フォント、文字サイズ、色)を指定
cv2.putText(image, class_name, (start_X, start_Y), cv2.FONT_ITALIC, (.005*image_width), (0, 0, 255))
# cv2.imshow('image', image)
cv2.imwrite("img/laptop_box_text.jpg", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
コードの説明をしていきます。
ダウンロードしておいた訓練済みモデルを読み込みます。`cv2.dnn.readNetFromTensorflow`を使います。
model.setInput(cv2.dnn.blobFromImage(image, size=(300, 300), swapRB=True))
`cv2.dnn.blobFromImage`を使って、blobという形に変換します。300*300のサイズに変換して、OpenCVのBGRからRGBに変換してます。正規化も行なっているみたい。
model.setInput(cv2.dnn.blobFromImage(image, size=(300, 300), swapRB=True))
outputには、モデルが予測した結果が入っています。outputの形式は(1,1,100,7)の形になっていて、3つ目にクラスID、4つ目にモデルが予測した確率が入っていますので、そこだけ取り出します。
# 画像から物体検出を行う output = model.forward() # outputは[1:1:100:7]のリストになっているため、後半の2つを取り出す detections = output[0, 0, :, :]
モデルが予測した確率が0.5以上ある場合に、クラス名と座標を取得する感じです。取得した座標とクラス名は、画像に書き込んでいます。
# detectionには[?,id番号、予測確率、Xの開始点、Yの開始点、Xの終了点、Yの終了点]が入っている。
for detection in detections:
# 予測確率を取り出し0.5以上か判定する。0.5以上であれば物体が正しく検出されたと判定する。
confidence = detection[2]
if confidence > .5:
# id番号を取り出し、辞書からクラス名を取り出す。
idx = detection[1]
class_name = classNames[idx]
# 検出された物体の名前を表示
print(" "+str(idx) + " " + str(confidence) + " " + class_name)
# 予測値に元の画像サイズを掛けて、四角で囲むための4点の座標情報を得る
axis = detection[3:7] * (image_width, image_height, image_width, image_height)
# floatからintに変換して、変数に取り出す。画像に四角や文字列を書き込むには、座標情報はintで渡す必要がある。
(start_X, start_Y, end_X, end_Y) = axis.astype(np.int)[:4]
# (画像、開始座標、終了座標、色、線の太さ)を指定
cv2.rectangle(image, (start_X, start_Y), (end_X, end_Y), (23, 230, 210), thickness=2)
# (画像、文字列、開始座標、フォント、文字サイズ、色)を指定
cv2.putText(image, class_name, (start_X, start_Y), cv2.FONT_ITALIC, (.005*image_width), (0, 0, 255))
実行結果
私のiPhoneで撮影した画像を使ってみます。
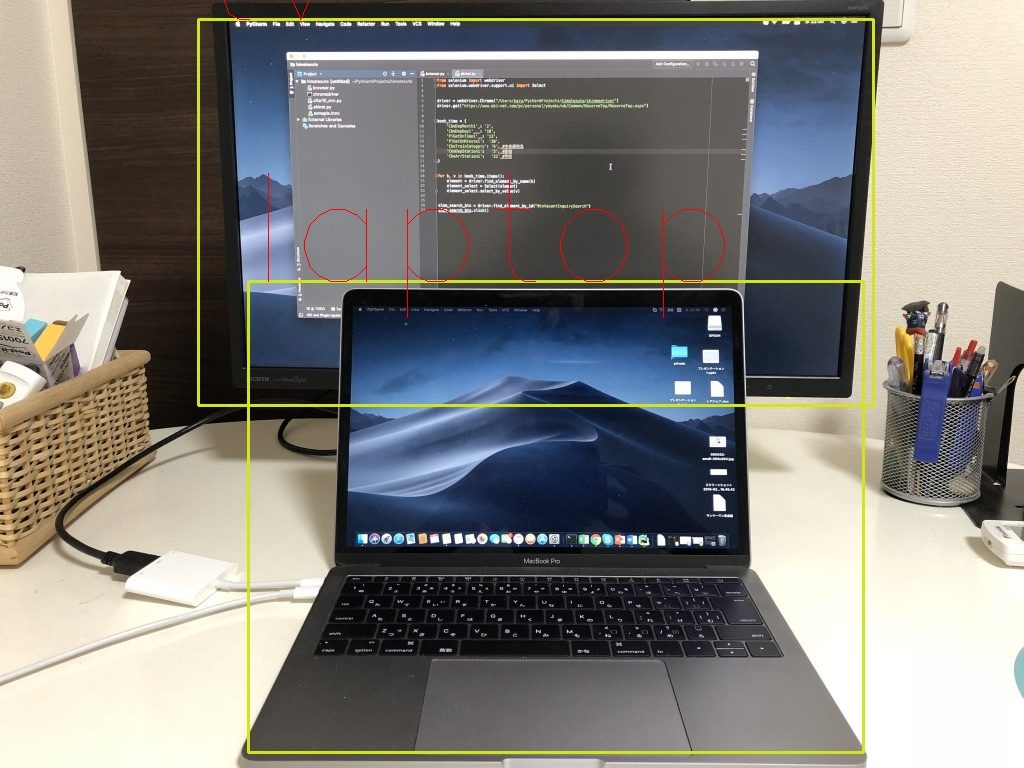
私の使っているMacとディスプレイ。
タイに行った時の飛行機。

タイにいたゾウ。

傘と人とゾウを検出しています。人の位置が少し違う感じですね。
とりあえず、物体検出APIは動いたので、今後はラズパイのカメラ+リアルタイム物体検出をやってみたいと思います。
前から思っていたのですが、海外のブログ記事は有用なものが多くて助かります。ヽ(・∀・)ノ
おわり。
参考
Real-Time Object Detection on Raspberry Pi Using OpenCV DNN and MobileNet-SSD:
https://heartbeat.fritz.ai/real-time-object-detection-on-raspberry-pi-using-opencv-dnn-98827255fa60
Github:
https://github.com/opencv/opencv/wiki/TensorFlow-Object-Detection-API






