
こんにちは、のっくんです。
今日は、Kaggleに糖尿病のデータがあったのでそのデータに対してディープラーニングをして、糖尿病かどうかを判別したいと思います。
使用するデータは、こちら。https://www.kaggle.com/uciml/pima-indians-diabetes-database
21歳以上のピマ・インディアン(女性)の糖尿病に関するデータだそうです。
ピマ・インディアンを調べてみると、
ピマ・インディアンと糖尿病
アメリカ、アリゾナ州に住むピマ・インディアン。人口の50%以上が糖尿病で、有病率の高さで世界的に有名です。60歳以上の女性では80%を超えています。彼らは氷河期の頃ベーリング海峡を渡りアジアから北米に移住した部族です。彼らは狩猟と採集や原始的な農業により生活の糧を得ていました。
20世紀初めヨーロッパ系アメリカ人が彼らの生活環境を破壊したため、多くのピマ・インディアンは保護地区で生活費の支給を受けるようになりました。その結果、欧米化した食事や運動不足により、肥満と糖尿病が急速に拡がっていきました。
一方、メキシコに住むピマ・インディアンはどうでしょう。彼らは今でも農業が中心で、昔ながらの生活を送っています。肥満も糖尿病もほとんど見られません。
このことは、糖尿病の発症には環境因子が大きく関わっていることを意味します。
https://kunichika-naika.com/information/hitori201403
つまり、50%以上が糖尿病で、糖尿病のメッカであるアリゾナ州に住むインド人女性のデータということですね。
なぜインド人がアメリカに住んでいるのでしょう。
まぁいいや。とりあえず、コードを書きつつ、データの中身を見ていきます。
[toc]
データセットの中身
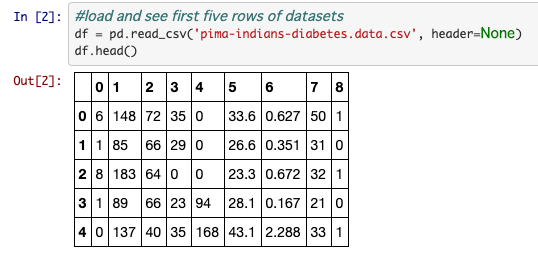
んで、何の数値かぱっと見、分からないので、調べてみました。左から順に、
- 妊娠した回数、グルコース、血圧(mm HG)、皮膚の厚さ、インスリン、BMI、Diabetes pedigree function(血統?)、年齢、ラベル(糖尿病は1、そうでなければ0)
私は医者でないので不明な数値がたくさんありますが、糖尿病の人って太ってるのでBMIだけ見れば判別できるのでは?と素人ながらに思ってしまいました。
余談はさておき、ラベル以外のデータとラベルに分割します。
df.drop(8,axis = 1)とすると、8列目を削除するという意味になります。axisを0にすると行を指定するようになります。
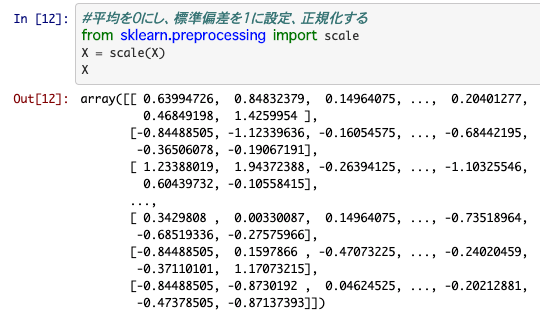
データの前処理 -スケーリング-
機械学習のデータはそのまま使うのではなく、スケールするのが望ましいです。
In practice we often ignore the shape of the distribution and just transform the data to center it by removing the mean value of each feature, then scale it by dividing non-constant features by their standard deviation.
https://scikit-learn.org/stable/modules/preprocessing.html
英語なのでアレですが、スケールというのは標準化のことで、平均値を引き算したり標準偏差を割り算して、いい感じのデータにしようってことです。
scikit-learnにこの機能がついているので利用しましょう。
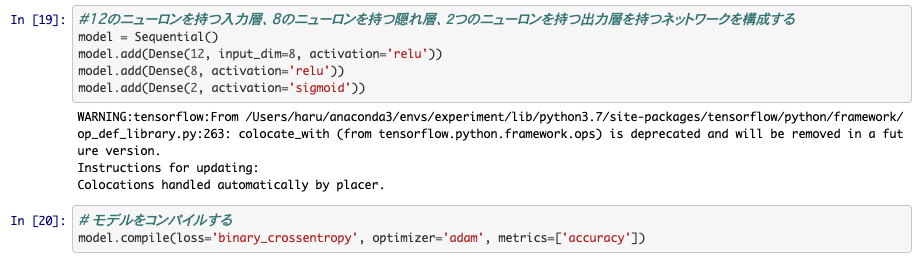
モデルの構築
ニューラルネットのモデルはシンプルです。入力層、隠れ層、出力層の3つから構成されます。入力の次元は8個のデータを使用するので8です。出力は糖尿病かそうでないかの2パターンなので2です。
2値分類なので、損失関数には、binary_crossentropyを使います。
エポック150,バッチサイズは10で学習します。データの次元が少ないので、CPUでも一瞬で計算が終わりますよ。
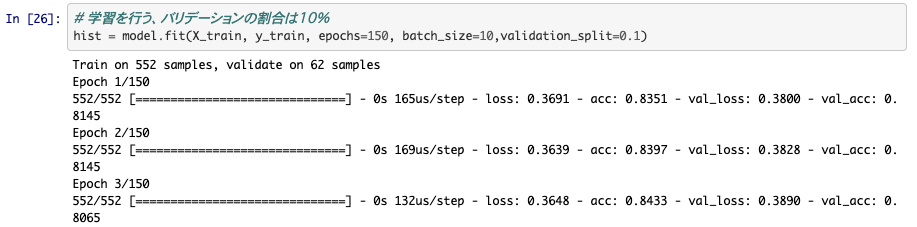
テストの結果と考察
テスト結果は、`model.evaluate`関数で計算できます。
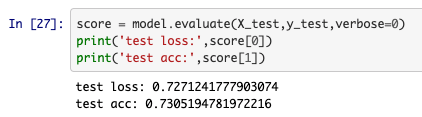
73%なのでそこそこでしょうか。あまり良くもないですが。
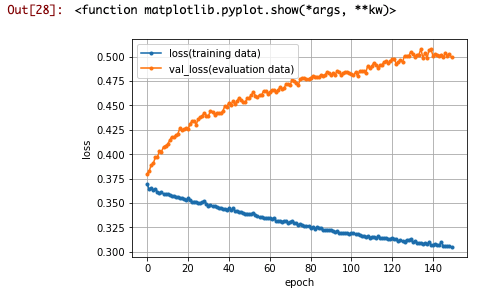
なんか、過学習しまくっているので、L2正規化とかドロップアウトを追加した方が良いかもしれません。
おわり。
参考
towardsdatascience,
scikit-learn,
https://scikit-learn.org/stable/modules/preprocessing.html
kaggle,








