こんにちは、のっくんです。
ゴールデンウィークいかがお過ごしでしょうか。
私は特にやることもないので家で引きこもってコーディングしていますw
今日は東京の23区のデータを集めて、簡単なデータ分析をやってみたいと思います。
やったみたことは以下の通り。
- ウィキペディアから東京23区のデータを取得する
- Geopyで地区名から位置情報を取得する
- Foursquare APIを使って周辺にある観光スポットを取得する
- レストランの位置情報を地図上に表示する
- 集めたデータの簡単な分析
まずは23区のデータがないと始まらないので、そのあたりを収集するところから始めるよ。
[toc]
東京23区データの取得(BeautifulSoup)
このあたりの情報は以下のサイトから取得します。
https://en.wikipedia.org/wiki/Special_wards_of_Tokyo
PythonのライブラリであるrequestsとBeautifulSoupを使いスクレイピングします。
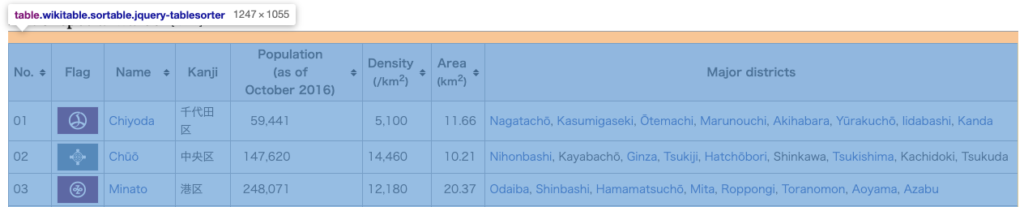
サイトに行くと以下のようなお宝情報(23区の名前、人口、密度、面積…)があるので、ここから必要な情報を取得します。
chromeの検証ツールを使い、テーブルの名前を取得します。
import requests
from bs4 import BeautifulSoup
response_obj = requests.get('https://en.wikipedia.org/wiki/Special_wards_of_Tokyo').text
soup = BeautifulSoup(response_obj)
Wards_Tokyo_Table = soup.find('table', {'class':'wikitable sortable'})
テーブルの列が8個ありますが23区の画像とかはいらないので、以下の情報だけ取り出します。
- 2:区の名前
- 4:人口
- 5:密度(/km2)
- 6:区の面積(km2)
- 7:主な都市名
主な都市名ですが、例えば、「港区だったらお台場」、「千代田区だったら永田町」のような感じですね。
掲載されている最初の都市名だけ取得します。
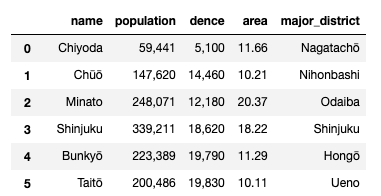
いらないspanタグや改行コードが入っているのでそれを除去しつつ、必要なデータを取り出しました。
こんな感じ。
位置情報データの取得(geopy)
次に得られた都市名からgeopyを使い位置情報を取得します。
geopyの使い方はシンプルで、都市名を入れるとその経度と緯度が返ってきます。
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="Tokyo")
location = geolocator.geocode("Nihonbashi")
print(location.latitude, location.longitude)
location = geolocator.geocode("Odaiba")
print(location.latitude, location.longitude)
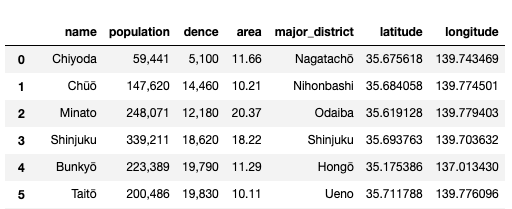
得られた情報をpandasに追加すると以下のような感じ。
Pythonだとサクサクっと書けるので、面白いですね。
今度はこの位置情報を使って、近隣のレストランを調べてみようと思います。
周辺スポットのデータ取得(FourSquare API)
foursquareが提供しているAPIを使って、周辺スポットのデータを取得します。
以下のサイトからIDとシークレットを取得します。
https://ja.foursquare.com/developers/apps
以下のような関数を作り、必要な情報をpandasのデータフレームで取得します。
import requests
radius = 1000
LIMIT = 100
def getNearbyVenues(names, latitudes, longitudes, radius=1000):
venues_list=[]
for name, lat, lng in zip(names, latitudes, longitudes):
print(name)
# create the API request URL
url = 'https://api.foursquare.com/v2/venues/explore?&client_id={}&client_secret={}&v={}&ll={},{}&radius={}&limit={}'.format(
CLIENT_ID,
CLIENT_SECRET,
VERSION,
lat,
lng,
radius,
LIMIT)
# make the GET request
results = requests.get(url).json()["response"]['groups'][0]['items']
# return only relevant information for each nearby venue
venues_list.append([(
name,
lat,
lng,
v['venue']['name'],
v['venue']['location']['lat'],
v['venue']['location']['lng'],
v['venue']['categories'][0]['name']) for v in results])
nearby_venues = pd.DataFrame([item for venue_list in venues_list for item in venue_list])
nearby_venues.columns = ['District',
'Dist_Latitude',
'Dist_Longitude',
'Venue',
'Venue_Lat',
'Venue_Long',
'Venue_Category']
return(nearby_venues)
位置情報(名前、緯度、経度)を指定すると、半径1kmの以内の観光スポットを教えてくれます。
取得したデータには、ホテルやカフェのデータが含まれるので、レストランの情報だけを以下のコードで抜き出してみました。
only_restaurant = venues[venues['Venue_Category'].str.contains('Restaurant')].reset_index(drop=True)
print ("レストランの数: ", only_restaurant.shape)
only_restaurant.head(10)

地図上に可視化する(folium)
`folium`を使って、渋谷にあるレストランの情報を地図上に可視化してみます。
r_map = folium.Map(location=[Tokyo_latitude, Tokyo_longitude], zoom_start=12)
# レストランの場所を地図上にプロット
for lat, lng, label in zip(df2['Venue_Lat'], df2['Venue_Long'],
df2['Venue']):
folium.Marker(location=[lat, lng], popup=label).add_to(r_map)
r_map
短いコードで書けるので便利ですね。
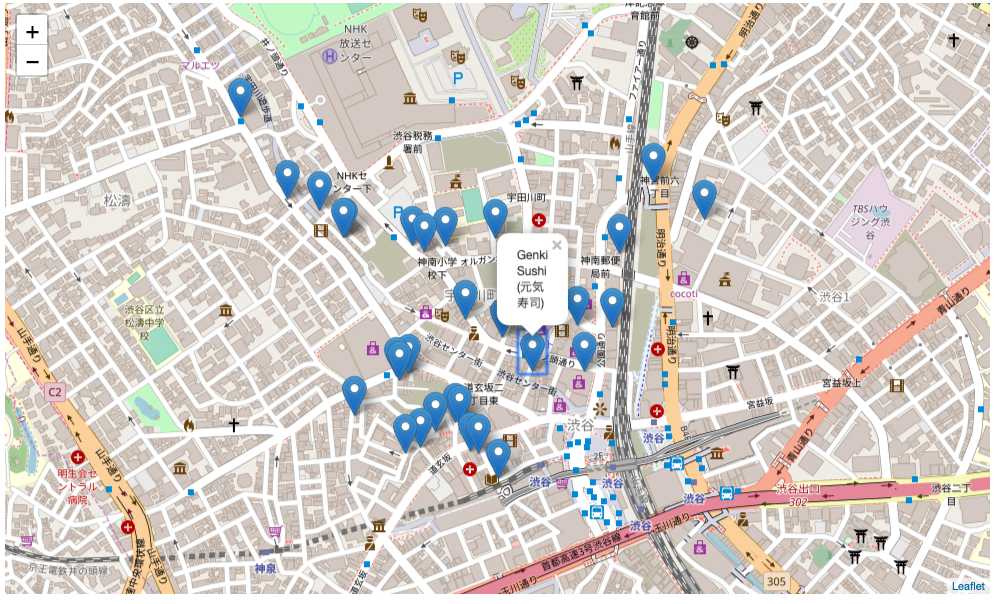
おまけ
渋谷、新宿、品川、永田町、お台場で、人が訪れている最も多い場所を表示してみました。
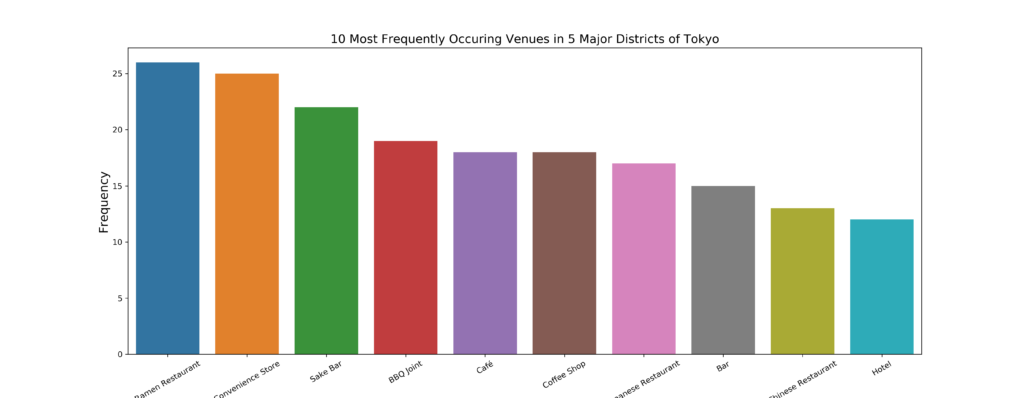
ラーメン屋、コンビニ、バー、BBQ屋、カフェ…の順に並んでいます。
レストランの数を比較してみると、
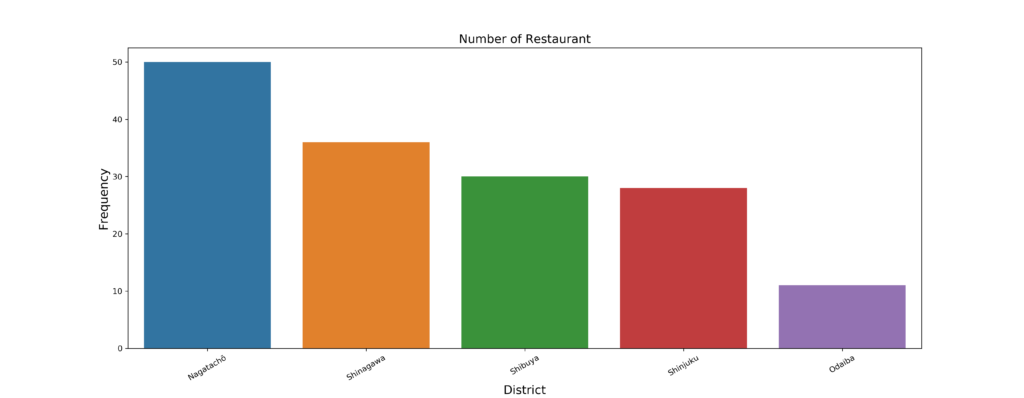
永田町、品川、渋谷、新宿、お台場の順で多いことがわかりました。
おわり。
参考
wikipedia,
https://en.wikipedia.org/wiki/Special_wards_of_Tokyo
towardsdatascience.com,