
こんにちは、のっくんです。
今日は機械学習を使って、フルーツの分類をしてみようと思います。
フルーツといっても画像データではなく、重さなどの数値データを使います。
以下のサイトにあったデータを使います。
中身はこんな感じ。
fruit_label fruit_name fruit_subtype mass width height color_score 1 apple granny_smith 192 8.4 7.3 0.55 1 apple granny_smith 180 8.0 6.8 0.59 1 apple granny_smith 176 7.4 7.2 0.60 2 mandarin mandarin 86 6.2 4.7 0.80 2 mandarin mandarin 84 6.0 4.6 0.79
重さ、横幅、高さ、色のスコアがあります。
目に見えないですが、タブで区切られているので区切り文字をタブ(\t)にして読み込みます。
df = pd.read_csv("fruit_data_with_colors.txt",sep="\t")
フルーツの名前の数を見るには以下のようにします。
print(df.groupby('fruit_name').size())
fruit_name
apple 19
lemon 16
mandarin 5
orange 19
dtype: int64
りんご、レモン、マンダリン、オレンジの4つの種類があることがわかりました。
マンダリンは5つしかないですね。
ラベルとデータに分解してみます。
pandasのデータフレームから複数の列を取り出すには、カラム名をリストで指定します。
X = df[["mass","width","height","color_score"]] y = df["fruit_label"]
データの分布を見るには以下のようにスキャッターマトリックスを作成します。
from matplotlib import cm
import matplotlib.pyplot as plt
cmap = cm.get_cmap('gnuplot')
scatter = pd.plotting.scatter_matrix(X, c = y, marker = 'o', s=40, hist_kwds={'bins':15}, figsize=(9,9), cmap = cmap)
plt.savefig('fruits_scatter_matrix')
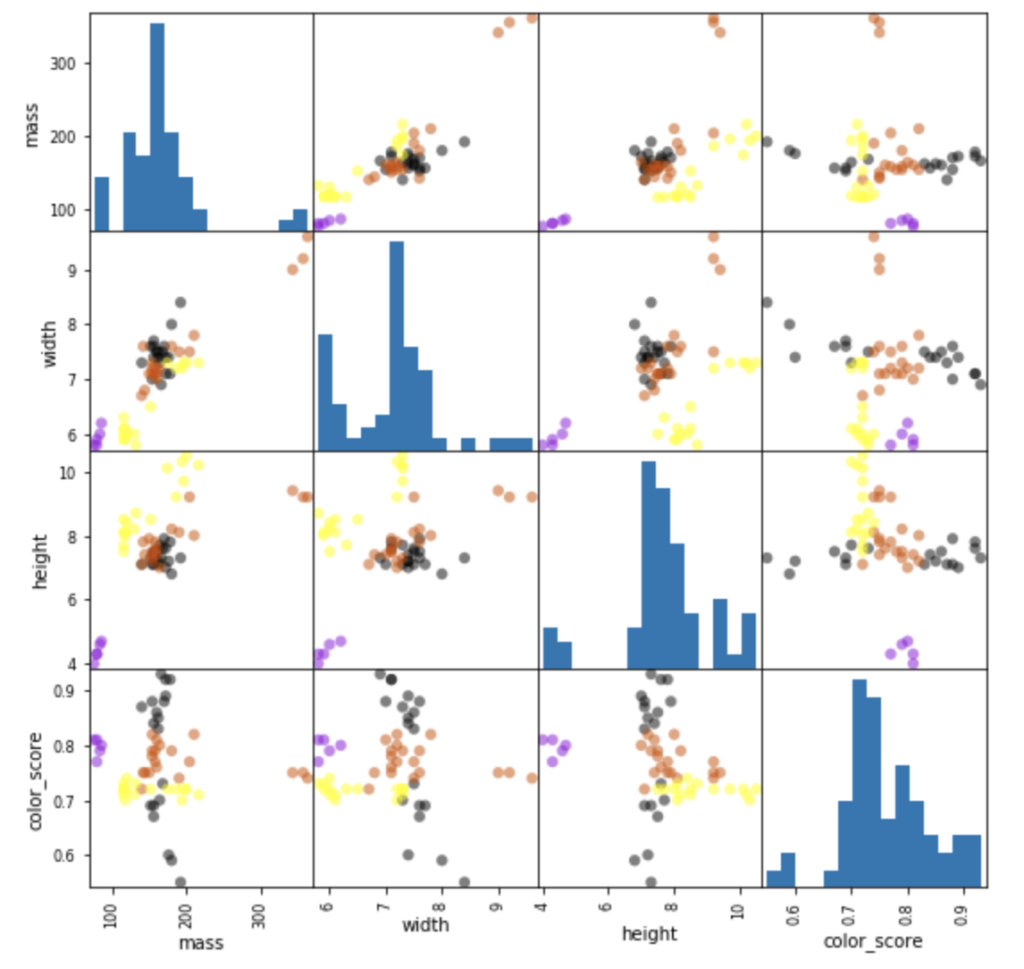
4つの点がグループ化できそうな感じがします。横幅と高さで見ると紫のマンダリンが小さいのですぐにわかりそうですね。
データの分割と標準化を行います。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test)
k-NN近傍法で分類してみます。
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
print('Accuracy of K-NN classifier on training set: {:.2f}'
.format(knn.score(X_train, y_train)))
print('Accuracy of K-NN classifier on test set: {:.2f}'
.format(knn.score(X_test, y_test)))
Accuracy of K-NN classifier on training set: 0.95 Accuracy of K-NN classifier on test set: 1.00
訓練95%,テスト100%の精度で分類できました。
おわり。
参考:








