
こんにちは、のっくんです。
今日はpandasを使って、スターバックス(スタバ)のデータを分析してみようと思います。
スタバの数の指標として、一人当たりのスタバ数を計算します。
人口がめちゃくちゃ多いのにスタバの数が少ないと数値は小さくなります。
逆に人口が少ないけれどスタバが多いと数値は大きくなります。
つまり、どこにスタバを出店するべきか決める際の指標になります。
数値が小さい場所に出店すれば、儲かることは間違いないでしょう。
[toc]
csvデータの読み込み
LA(ロサンジェルス)にあるスタバの各店舗情報とLAの人口情報を使って、一人あたりのスタバ数を求めます。
- LAのスタバの店舗データ(郵便番号含む)
- LAの人口データ(郵便番号含む)
1人あたりのスタバの数は、以下の式で求められます。
一人当たりのスタバ数 = お店の数/人口
これを求めるために、pandasでデータを加工して2つのデータをマージしていきます。
まずは、人口データをみてみましょう。

郵便番号ごとの人口が記載されています。
次に、スタバの店舗データをみてみましょう。
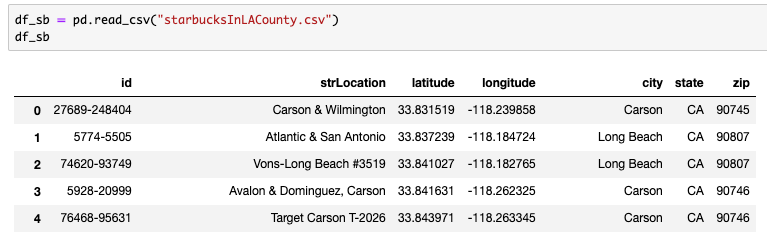
最初のデータは郵便番号ごとの人口なのに対して、店舗データは郵便番号ごとの店舗数になっていません。
特定のカラムにおける出現回数のカウント
まずは郵便番号ごとの店舗数を求めることから初めていきます。
- 郵便番号ごとの店舗数を求める
- いらないカラムの削除
- カラム名とインデックス名を調整
以上の処理をするコードが以下の通り。
df_count = df_sb.groupby("zip").count()
df_count = df_count.drop(['strLocation','latitude','longitude',"city","state"], axis=1)
df_count.columns=["numStore"]
df_count.index.names = ['zipcode']
df_count
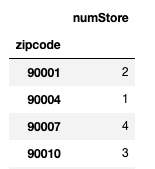
郵便番号ごとの店舗数が求められました。
データフレームのマージ
次に、人口データと店舗データをマージしましょう。
左結合、つまり人口データに対して店舗データをマージします。
なぜかというと、人口データの方が郵便番号が多いからです。
左結合を指定すると、スタバがないエリアの郵便番号の行は欠損値になります。
df_merged = pd.merge(df_pop,df_count,on="zipcode",how="left") df_merged
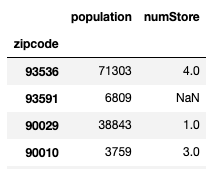
カラム同士の割り算
次に、一人あたりの店舗数を求め、それを新しいカラムに割り当てます。
一人あたりの店舗数は、numStorePerPopというカラム名にします。
df_merged['numStorePerPop'] = df_merged['numStore']/df_merged['population'] df_merged
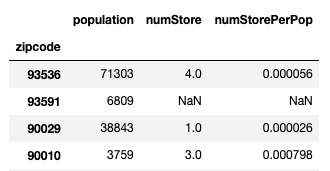
これで求めたい値が計算できました。
インデックスのソート
ついでに、zipcodeを小さい順に並べておきましょう。
indexをソートするには以下のようにします。
df_merged.sort_index(inplace=True) df_merged
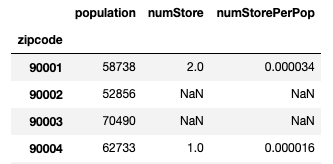
こんな感じ。
次はこのデータを使って、コロプレスマップを作ってみます。
【Pandas】スタバのデータを分析してみた【コロプレスマップ】
おわり。
参考
使用したスタバのデータは以下の記事で紹介されているものを使いました。
https://towardsdatascience.com/joining-data-sources-8ca72f19747











