
さて、前回に引き続き、スタバのデータを分析してみます。
前回の記事では、一人当たりの店舗数をPandasを使って求めるところまでやりました。
【Pandas】スタバのデータを分析してみた【一人当たりの店舗数を求める】
今日はそのデータを地図上に可視化してみたいと思います。
コロプレス図という統計数値を地図にプロットしたものを作っていきます。
[toc]
非数(nan)や無限大(inf)が含まれる行を削除する
さて、前回作ったデータフレーム(ソート前)は以下の通りでした。
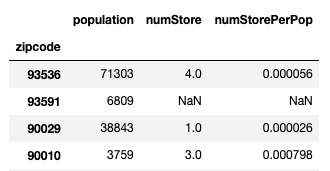
このままだとコロプレス図にできないので、以下の前処理を施します。
- 欠損値(NaN)が含まれる行を削除する
- 無限大が含まれる行を削除する
- zipcodeのカラムを作る
特に忘れがちなのが無限大(inf)ですね。割り算の過程で発生したのでしょう。これを削除しておかないと地図ライブラリFoliumにデータフレームを渡した時にエラーが出ます。
import numpy as np # ソート df_merged.sort_index(inplace=True) # zipcodeのstringタイプのカラムを作る df_merged['zipcode'] = [str(z) for z in df_merged.index] # 欠損地を消す df_merged = df_merged.dropna() #無限大を消す df_merged = df_merged[df_merged.numStorePerPop != np.inf]

これでpandasのデータフレームは準備完了です。
Foliumのベースマップを作る
Foliumのベースマップを作るには、地図の緯度と経度が必要になります。
GeoIPを作って取得します。
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="test-dayo")
location = geolocator.geocode("Los Angeles")
LA_location = [location.latitude,location.longitude]
次に、ベースマップを作成します。
import folium m = folium.Map(location=LA_location)
コロプレス図の作成
コロプレス図を作るには、geojsonファイルが必要です。これは地図上にエリアごとの区切りをプロットするものです。以下のサイトに置いてあります。
https://github.com/ritvikmath/StarbucksStoreScraping
データフレームやカラム、色、geojsonファイルを指定し、HTML形式で出力する感じです。
geojson = "laZips.geojson"
m.choropleth(
geo_data=geojson,
name='choropleth',
data=df_merged,
columns=['zipcode','numStorePerPop'],
key_on='feature.properties.zipcode',
fill_color='YlGn',
fill_opacity=1
)
m.save('laChoropleth.html')
出力されたHTMLはこんな感じ。
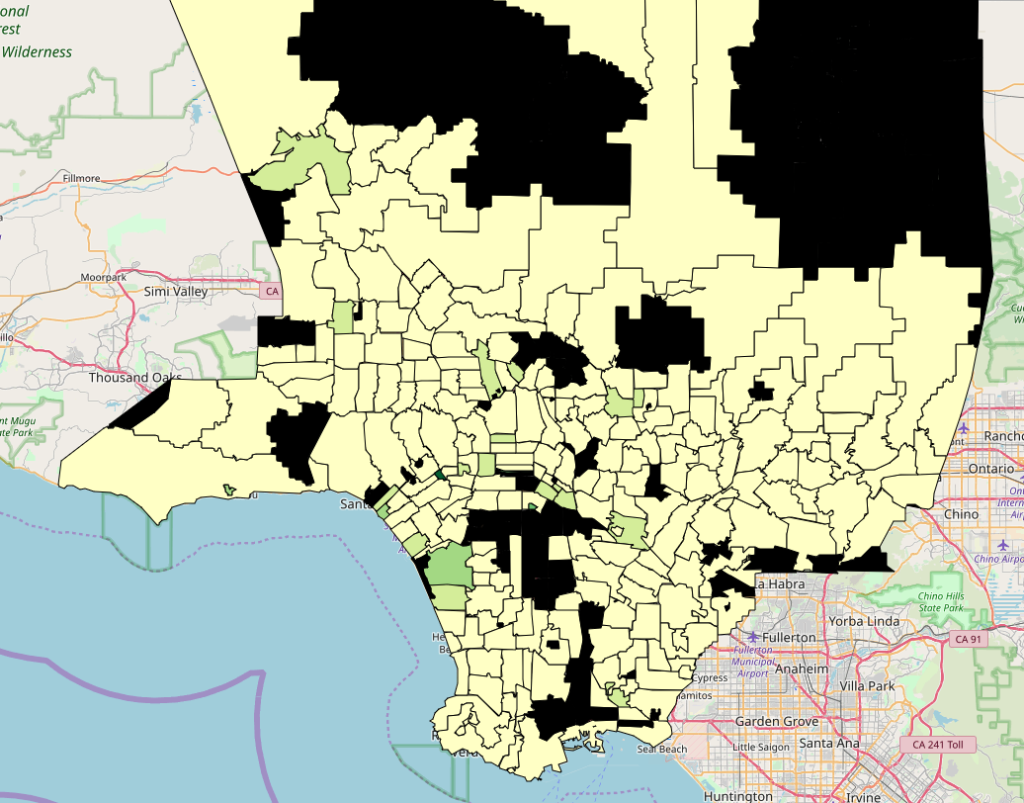
外れ値の影響で、ほとんど同じ色になってしまいました。
外れ値だと思われる上位10%を削除します。
q = df_merged["numStorePerPop"].quantile(0.9) df_merged_remove = df_merged[df_merged["numStorePerPop"] < q]
再度コロプレス図を作ると、
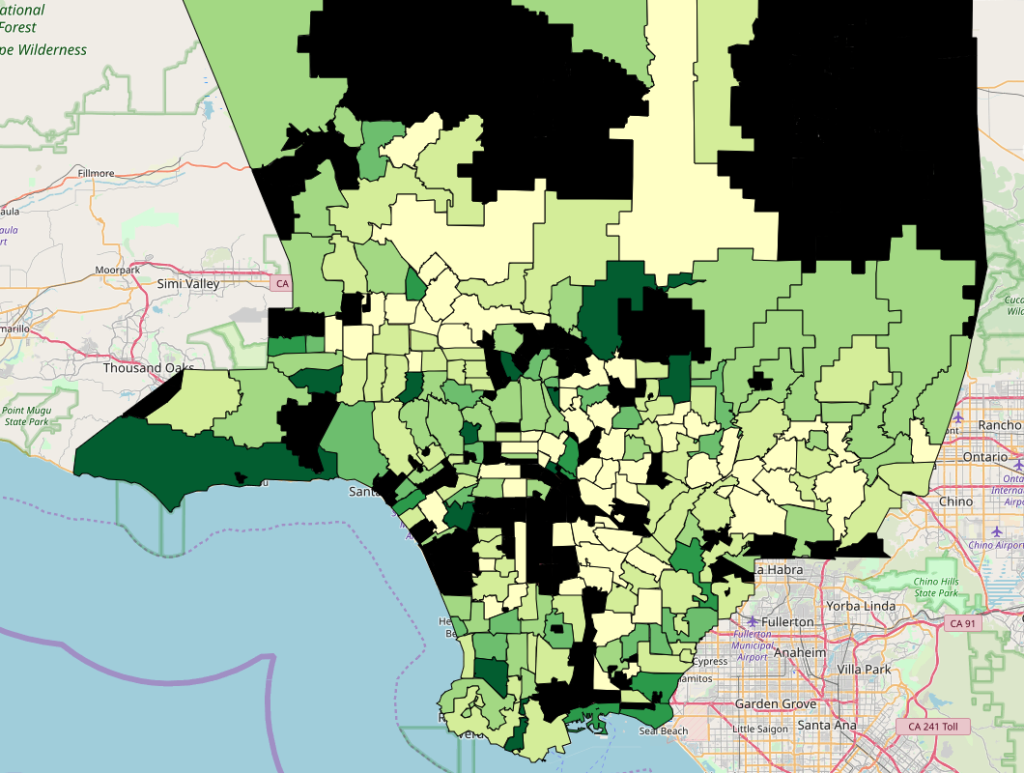
良い感じにできました。
緑が濃くなっている場所ほど、一人当たりのスタバの数が多くなってます。
黒いエリアは、スタバが無い、人口データが無い、もしくは外れ値として削除された場所です。
おわり。
参考
https://towardsdatascience.com/joining-data-sources-8ca72f19747










