皆さんは、Fashion-MNISTを知っているでしょうか。
MNISTデータセットといえば、0から9の手書き数値の画像データセットだ。

昔このデータセットを使ってディープラーニングをやってみたことがあった。詳しくは以下の記事を参照。
この手書き数字を服や靴にしたのがFashion-MNISTだ。
最近になってこのデータを提供しているgithubを発見した。
https://github.com/zalandoresearch/fashion-mnist
この提供している人によると、
「MNISTは簡単すぎて高精度がでまくっているので、もう少し難しいデータセットを用意したよ〜」ということらしい。
面白そうなので、このデータセットでディープラーニングを試してみることにした。
[toc]
データセットの中身
まずはじめに上記のレポジトリをクローンして準備完了。容量が大きいので10分ほど時間かかりました。
まず、このデータセットを読み込むところから始める。
GithubのReadmeのUsageをみると、データセットの読み込み方が書いてあるので、その通りにコードを書いてみる。
データセットの画像とラベルもついでに表示させてみよう。
utils/mnist_reader.py が置いてあるディレクトリと同じ場所に新しくjupyternotebookのファイル(.ipynb)を作成しコードを書いていきます。
import mnist_reader
X_train, y_train = mnist_reader.load_mnist('../data/fashion', kind='train')
X_test, y_test = mnist_reader.load_mnist('../data/fashion', kind='t10k')
import matplotlib.pyplot as plt
%matplotlib inline
for i in range(10):
plt.subplot(2,5,i+1)
plt.imshow(X_train[i].reshape(28,28),cmap=None)
print(y_train[i])
plt.show()
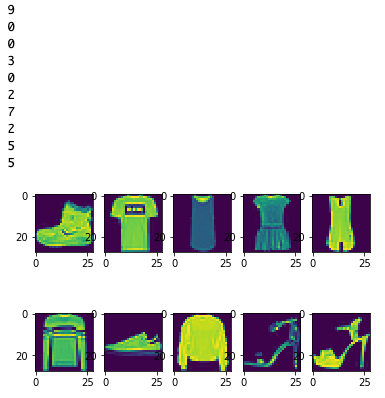
最初の数値はラベルだ。ラベルと服の対応表がこれまたreadmeに書いてあるので見てみると、
| Label | Description |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
Ankle boot(アンクルブーツ), T-shirt(ティーシャツ), T-shirt, Dress(ドレス) … の順に並んでいる。
ちなみに、アンクルブーツというのはくるぶし丈のブーツのことらしい。
画像はintで読み込んでいたのでfloatに変換、ラベルはベクトルに変換する。
MNISTだと(28,28)の2次元配列として画像を読み込んでいたが、MNIST_fashionのmnist_reader.pyではすでに1次元のベクトルとして画像データを読み込んでくれているため次元数の変換は必要ない。
num_classes = 10
# floatに変換
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# 0-1に正規化
X_train /= 255
X_test /= 255
# クラス数をセット
y_train = keras.utils.to_categorical(y_train,num_classes)
y_test = keras.utils.to_categorical(y_test,num_classes)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
配列の形を出力してみる
(60000, 784) (10000, 784) (60000, 10) (10000, 10)
これで学習に使用する6万枚の訓練用画像と1万枚のテスト用画像が用意できた。
機械学習をしてみる
機械学習用のネットワークを組んでみる。
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import RMSprop
from keras.callbacks import EarlyStopping, CSVLogger
model = Sequential()
model.add(Dense(512,input_shape=(784,)))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(10))
model.add(Activation('softmax'))
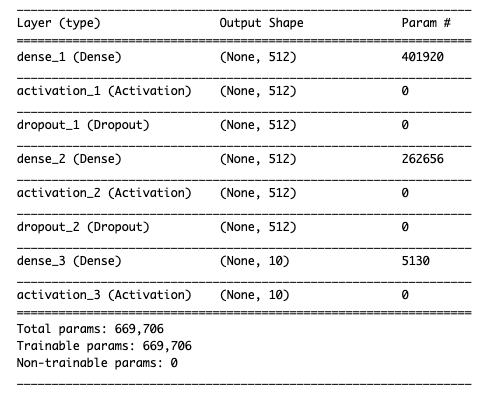
model.summary()
784次元のデータを入力し、最終的には10個のカテゴリに分類する。
csv_loggerは学習結果のログを残してくれるものだが必要ないかもしれない。
訓練用データのうち、0.1、つまり10%を検証用データとして使用する。
#訓練データの1個のデータ数
batch_size = 128
# 誤差逆伝播法の繰り返しの回数
epochs = 20
model.compile(loss="categorical_crossentropy",
optimizer=RMSprop(),
metrics=['accuracy'])
es = EarlyStopping(monitor='val_loss',patience=2)
csv_logger = CSVLogger('training.log')
hist = model.fit(X_train,y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1,
callbacks=[es,csv_logger])

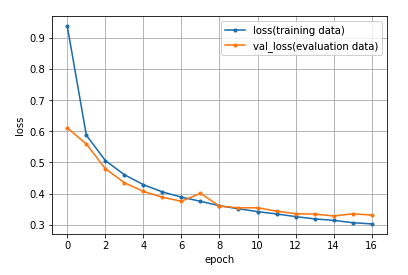
最初の方だけ画像を貼っておきます。実際にはEarlyStoppingを使っているので、17エポック目で終了しました。
テスト用画像を用いてテストしましょう。
score = model.evaluate(X_test,y_test,verbose=0)
print('test loss:',score[0])
print('test acc:',score[1])
test loss: 0.35610517823696136 test acc: 0.8704
そこそこの精度ですが、もう少しあげたいですね。MNISTだと90%後半の精度が出ていたので、このファッションデータセットはより難しいことになります。
学習結果を可視化するとこんな感じ。
おわり。